
ShareAI AI Gateway vs Vercel AI Gateway: What It Is, Why It Matters, and How ShareAI Differs
AI Gateway is quickly becoming the missing layer between apps and a messy world of model vendors, keys, quotas, and outages. This guide explains what an AI gateway is, summarizes the Vercel AI Gateway, and shows how ShareAI’s open network, 70% provider payouts, and BYOI (Bring Your Own Infrastructure) with Priority over my Device create a different path for teams that need compliance, elasticity, and choice.
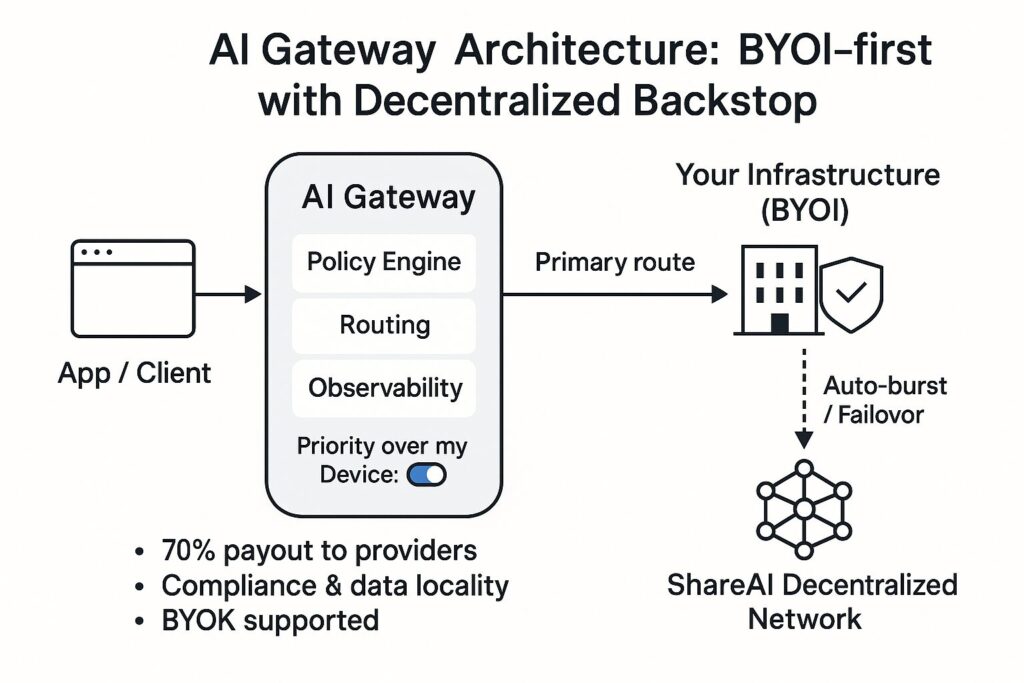
What is an AI Gateway (and why teams use one)
An AI gateway sits between your application and many model providers. It offers a single endpoint, policy-based routing (cost, latency, compliance), unified key and rate-limit management, automatic failover, and end-to-end observability. For production apps (agents, RAG, chat, search) it reduces vendor lock-in and keeps your code from hardwiring to one API.
Vercel AI Gateway: the quick take
Vercel announced its gateway on May 20, 2025 to unify access to many models behind one endpoint and the AI SDK. It emphasizes simple model switching, failover, and low-latency routing, with bring-your-own-key and no token markup called out in independent coverage. See the original post and recap: Vercel blog and InfoQ summary.
Where Vercel fits best: teams already standardized on Vercel + AI SDK that want a polished, single-vendor gateway inside that ecosystem with built-in logs, metrics, and failover.
How ShareAI’s Gateway differs
1) Open network (not just “big” inference vendors)
ShareAI is the people-powered AI API. Any qualified provider (community or company) can participate, so you’re not limited to a handful of centralized clouds. That means broader model choice, specialized hardware, and regional diversity. Compare options on the Model Marketplace or recruit new providers via the Provider Guide.
2) Provider-friendly economics (70% payout per inference)
ShareAI pays providers 70% of every inference. Incentives for uptime and quality grow network capacity while keeping prices efficient. Providers can run idle-time or always-on, set prices, and even donate a percentage to NGOs.
| Item | Value |
|---|---|
| Price billed to user | $1.00 |
| Paid to provider (70%) | $0.70 |
| ShareAI service & overhead | $0.30 |
3) BYOI with compliance-priority routing (“Priority over my Device”)
Bring your own infrastructure (on-prem or cloud) and keep sensitive workloads under your control. With the Priority over my Device toggle, your infra runs first; ShareAI only backstops when you need headroom—acting like a global load balancer. This keeps data locality and compliance simple while preserving elasticity.
Enable Priority over my Device (per API key)—open the API Key page in Console and toggle Priority over my Device for the key used by your app. When ON, ShareAI routes to your connected devices first; when none qualify, requests fall back to the decentralized network. See the Priority over my Device guide and the Console User Guide.
4) Instant scale + idle monetization
When traffic spikes, you burst into ShareAI’s decentralized network with zero warm-up. When your infra is idle, you can opt-in to earn by contributing capacity back to the network. It’s a win for orgs (instant scale and compliance), a win for providers (earnings), and a win for users (more choice on cost/latency).
Vercel AI Gateway vs ShareAI: side-by-side
| Capability | Vercel AI Gateway | ShareAI |
|---|---|---|
| Network breadth | Single endpoint for many models across major vendors (details). | Open network: major vendors plus independent/community providers (browse models). |
| BYOI & on-prem priority | Routing/reliability focus; SDK-centric. BYOK highlighted in coverage (InfoQ). | BYOI-first. Per-key toggle Priority over my Device makes your infra the first hop (how it works). |
| Failover | Automatic failover across providers (InfoQ). | Decentralized backstop across many providers/regions; policy-driven overflow. |
| Economics | BYOK with 0% token markup in reporting (InfoQ). | 70% payout to providers; transparent marketplace incentives. |
| Observability | Logs, metrics, cost tracking baked-in. | Request-level telemetry + marketplace signals (latency, uptime, reputation). |
| Developer experience | Tight AI SDK integration; minimal code to switch models. | REST/SDKs, policy controls in Console; quickstart in the API Reference. |
| Best fit | Vercel-native stacks wanting consolidated gateway + SDK DX. | Teams needing compliance-priority BYOI, decentralized elasticity, and provider earnings. |
How ShareAI routes under the hood
Request flow: (1) Policy & key check — the per-key toggle determines your first hop. (2) Compliance-priority routing — if your cluster/device is online and model-eligible, it serves the request. (3) Health/latency checks continuously monitor performance. (4) Decentralized fallback — overflow to ShareAI’s network when needed.
Provider onboarding & quality: join as Community or Company with Windows/Ubuntu/macOS/Docker installers; reputation considers uptime, latency, and benchmark tiers. Providers control pricing and gain exposure by meeting SLOs. See the Provider Guide.
Quick start: use ShareAI as your AI Gateway
- Create an API key in Console.
- Toggle Priority over my Device ON for that key if your infra must run first.
- Send a request using the API quickstart or try it in the Playground.
curl -X POST https://api.shareai.now/v1/chat/completions \
-H "Authorization: Bearer $SHAREAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-4.1-mini",
"messages": [{"role":"user","content":"Summarize our SOC2 controls in 5 bullets"}]
}'From here, swap models by changing the model identifier. Watch latency, cost, and routing in the Console User Guide, then explore new releases in Releases.
When to choose ShareAI over Vercel AI Gateway (and when not to)
Choose ShareAI if you need BYOI with compliance-priority routing (Priority over my Device), decentralized elasticity for traffic spikes, and provider/org earnings (70% payout, idle-time monetization).
Choose Vercel AI Gateway if you want a Vercel-native experience with the AI SDK, consolidated billing/observability inside that platform, and straightforward failover baked in (InfoQ recap).

