
EmbeddingGemma is now on ShareAI
We’re announcing that EmbeddingGemma, Google’s compact open embedding model, is now available on ShareAI.
At 300 million parameters, EmbeddingGemma delivers state-of-the-art performance for its size. It’s built from Gemma 3 with T5Gemma initialization and uses the same research and technology behind the Gemini models. The model produces vector representations of text, making it well-suited for search and retrieval tasks, including classification, clustering, and semantic similarity. It was trained with data in 100+ spoken languages.
Why it matters
The model’s small size and on-device focus make it practical to deploy in environments with limited resources—mobile phones, laptops, or desktops—democratizing access to state-of-the-art AI models and fostering innovation for everyone.
Benchmark
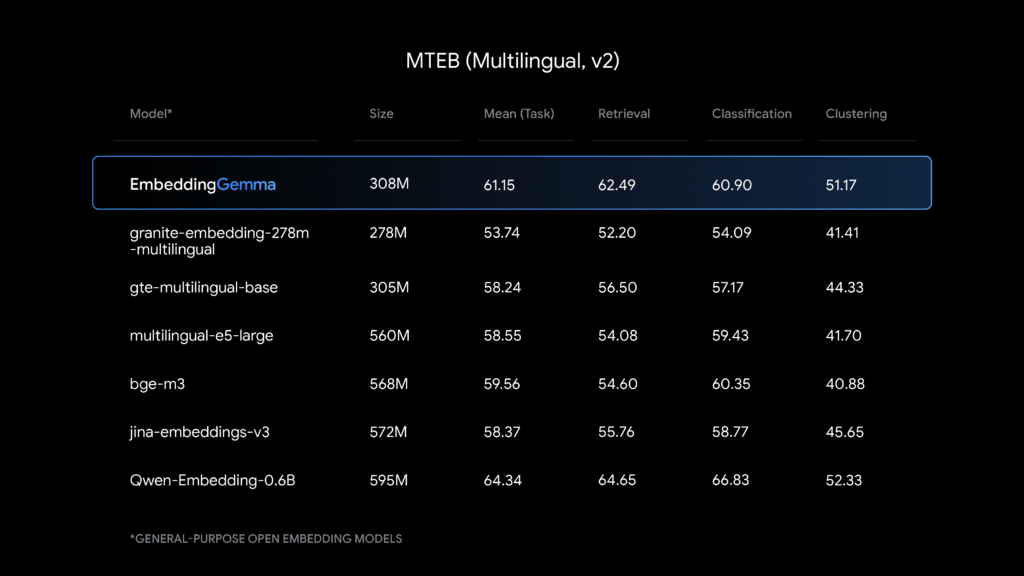
Training dataset
EmbeddingGemma was trained with data in 100+ spoken languages.
- Web documents
A diverse collection of web text ensures exposure to broad linguistic styles, topics, and vocabulary. The dataset includes content in 100+ languages. - Code and technical documents
Including programming languages and specialized scientific content helps the model learn structure and patterns that improve understanding of code and technical questions. - Synthetic and task-specific data
Curated synthetic data teaches specific skills for information retrieval, classification, and sentiment analysis, fine-tuning performance for common embedding applications.
This combination of diverse sources is crucial for a powerful multilingual embedding model that can handle a wide range of tasks and data formats.
What you can build
Use EmbeddingGemma for search and retrieval, semantic similarity, classification pipelines, and clustering—especially when you need high-quality embeddings that can run on constrained devices.
Reference
Available now on ShareAI.
Run it. Test it. Ship it.

