
Aktualisiert März 2026
Entwickler wählen Anfrage für ein einziges, OpenAI-kompatibles Gateway über viele LLM-Anbieter sowie Routing, Analysen und Governance. Aber wenn Ihnen Marktplatztransparenz vor jeder Route (Preis, Latenz, Betriebszeit, Verfügbarkeit), strikte Edge-Richtlinien, oder ein selbstgehosteter Proxy, wichtiger sind, könnten diese Requesty-Alternativen.
besser zu Ihrem Stack passen. TeilenAI Dieser Käuferleitfaden ist geschrieben, wie es ein Entwickler tun würde: spezifische Kompromisse, klare Schnellentscheidungen, tiefgehende Analysen, Gegenüberstellungen und ein Copy-Paste-.
Schnellstart, damit Sie noch heute loslegen können.
Requesty verstehen (und wo es möglicherweise nicht passt). Requesty ist ein LLM Gateway. Sie richten Ihren OpenAI-kompatiblen Client auf einen Requesty-Endpunkt aus und leiten Anfragen über mehrere Anbieter/Modelle weiter – oft mit Failover, Analysen und Richtlinienleitplanken. Es ist darauf ausgelegt, ein zentraler Ort zu sein, um Nutzung zu verwalten, Kosten zu überwachen und Governance über Ihre KI-Aufrufe durchzusetzen.
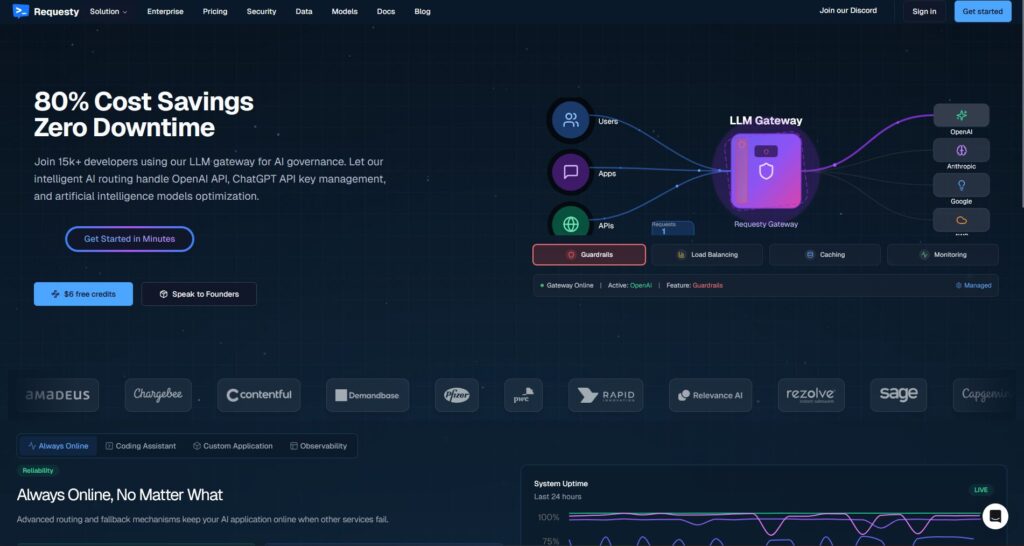
Warum Teams es wählen.
- Eine API, viele Anbieter. Reduzieren Sie SDK-Wildwuchs und zentralisieren Sie die Beobachtbarkeit.
- Failover & Routing. Halten Sie die Betriebszeit stabil, selbst wenn ein Anbieter ausfällt.
- Unternehmens-Governance. Zentrale Richtlinien, organisationsweite Kontrollen, Nutzungsbudgets.
Wo Requesty möglicherweise nicht passt.
- Sie möchten Marktplatztransparenz vor jeder Route (sehen Sie Preis, Latenz, Betriebszeit, Verfügbarkeit pro Anbieter jetzt und wählen Sie dann).
- Sie benötigen Richtlinie auf Edge-Niveau in Ihrem eigenen Stack (z. B. Kong, Portkey) oder Selbsthosting (LiteLLM).
- Ihr Fahrplan erfordert breite multimodale Funktionen unter einem Dach (OCR, Sprache, Übersetzung, Dokumentenparsing) über LLM-Chat hinaus – wo ein Orchestrator wie ShareAI besser geeignet sein könnte.
Wie man eine Requesty-Alternative auswählt
1) Gesamtkosten des Eigentums (TCO). Hören Sie nicht bei $/1K Tokens auf. Beziehen Sie Cache-Trefferquoten, Wiederholungen/Fallbacks, Warteschlangen, Evaluator-Kosten, Overhead pro Anfrage und die Betriebsbelastung durch Beobachtbarkeit/Alarme ein. Der “günstigste Listenpreis” verliert oft gegen einen Router/Gateway, der Verschwendung reduziert.
2) Latenz & Zuverlässigkeit. Bevorzugen Sie regionsbewusstes Routing, Warm-Cache-Wiederverwendung (bleiben Sie beim selben Anbieter, wenn das Prompt-Caching aktiv ist), und präzise Fallbacks (429er erneut versuchen; bei Timeouts eskalieren; Fan-Out begrenzen, um doppelte Ausgaben zu vermeiden).
3) Beobachtbarkeit & Governance. Wenn Leitplanken, Prüfprotokolle, Schwärzung und Richtlinien am Rand wichtig sind, ist ein Gateway wie Portkey oder Kong KI-Gateway oft stärker als ein reiner Aggregator. Viele Teams kombinieren Router + Gateway für das Beste aus beiden.
4) Selbstgehostet vs. verwaltet. Bevorzugen Sie Docker/K8s/Helm und OpenAI-kompatible Endpunkte? Siehe LiteLLM (OSS) oder Kong KI-Gateway (Enterprise-Infrastruktur). Möchten Sie gehostete Geschwindigkeit + Marktplatz-Sichtbarkeit? Siehe TeilenAI (unsere Wahl), OpenRouter, oder Vereinheitlichen.
5) Breite über Chat hinaus. Wenn Ihre Roadmap OCR, Sprache-zu-Text, Übersetzung, Bildgenerierung und Dokumenten-Parsing unter einem Orchestrator umfasst, TeilenAI kann die Lieferung und das Testen vereinfachen.
6) Zukunftssicherung. Wählen Sie Tools, die Modell-/Anbieterwechsel schmerzlos machen (universelle APIs, dynamisches Routing, explizite Modell-Aliasse), damit Sie neuere/günstigere/schnellere Optionen ohne Neuschreibungen übernehmen können.
Beste Requesty-Alternativen (schnelle Auswahl)
TeilenAI (unsere Wahl für Marktplatztransparenz + Builder-Ökonomie)
Eine API über 150+ Modelle mit sofortigem Failover und einem Marktplatz das Preis, Latenz, Betriebszeit, Verfügbarkeit bevor Sie routen,. Anbieter (Community oder Unternehmen) behalten der Großteil des Umsatzes, Anreize mit Zuverlässigkeit ausrichten. Starten Sie schnell in der Spielplatz, greifen Sie Schlüssel in der Konsole, und lesen Sie die Dokumentation.
Eden KI (multimodaler Orchestrator)
Einheitliche API über LLMs hinweg plus Bild, OCR/Dokumentenparsing, Sprache und Übersetzung – zusammen mit Modellvergleich, Überwachung, Caching und Batch-Verarbeitung.
OpenRouter (cache-bewusstes Routing)
Gehosteter Router über viele LLMs hinweg mit Prompt-Caching und Anbieterbindung zur Wiederverwendung warmer Kontexte; wechselt zurück, wenn ein Anbieter nicht verfügbar wird.
Portkey (Richtlinien- & SRE-Operationen am Gateway)
KI-Gateway mit programmierbaren Fallbacks, Ratenbegrenzungs-Playbooks, und einfacher/semantischer Cache, plus detaillierte Traces/Metriken für Produktionskontrolle.
Kong KI-Gateway (Edge-Governance & Audit)
Bringen KI-Plugins, Richtlinien, Analysen in das Kong-Ökosystem; passt gut zu einem Marktplatz-Router, wenn zentrale Steuerungen über Teams hinweg benötigt werden.
Vereinheitlichen (datengetriebener Router)
Universelle API mit Live-Benchmarks zur Optimierung von Kosten/Geschwindigkeit/Qualität nach Region und Arbeitslast.
Orq.ai (Experimentierung & LLMOps)
Experimente, Evaluatoren (einschließlich RAG Metriken), Bereitstellungen, RBAC/VPC – ideal, wenn Evaluierung und Governance zusammengeführt werden müssen.
LiteLLM (selbstgehosteter Proxy/Gateway)
Open-Source, OpenAI-kompatibler Proxy mit Budgets/Limits, Logging/Metriken und einer Admin-UI. Bereitstellung mit Docker/K8s/Helm; Sie verwalten den Betrieb selbst.
Detaillierte Einblicke: Top-Alternativen
ShareAI (Menschenbetriebene KI-API)

Was es ist. Ein Anbieter-zentriertes KI-Netzwerk und eine einheitliche API. Durchsuchen Sie einen großen Katalog von Modellen/Anbietern und routen Sie mit sofortiges Failover. Der Marktplatz zeigt Preis, Latenz, Betriebszeit und Verfügbarkeit an einem Ort, damit Sie den richtigen Anbieter vor jeder Route auswählen können. Starten Sie im Spielplatz, erstellen Sie Schlüssel im Konsole, und folgen Sie den API-Schnellstart.
Warum Teams es wählen.
- Marktplatztransparenz — sehen Sie Anbieter Preis/Latenz/Verfügbarkeit/Betriebszeit im Voraus.
- Resilienz-als-Standard — schnell Failover zum nächstbesten Anbieter, wenn einer ausfällt.
- Erbauer-ausgerichtete Wirtschaftlichkeit — der Großteil der Ausgaben fließt an GPU-Anbieter, die Modelle online halten.
- Reibungsloser Start — Modelle durchsuchen, testen im Spielplatz, und versenden.
Anbieter-Fakten (verdienen durch das Online-Halten von Modellen). Jeder kann Anbieter werden (Community oder Unternehmen). Onboarding über Windows/Ubuntu/macOS/Docker. Beitragen Leerlaufzeit-Ausbrüche oder ausführen immer eingeschaltet. Wählen Sie Anreize: Belohnungen (Geld), Austausch (Tokens/AI Prosumer), oder Mission (spenden Sie % an NGOs). Während Sie skalieren, Ihre eigenen Inferenzpreise festlegen festlegen und bevorzugte Sichtbarkeit. Details: Anbieterleitfaden.
Ideal für. Produktteams, die möchten Marktplatz-Transparenz, Resilienz, und Raum zum Wachsen in den Providermodus – ohne Anbieterbindung.
Eden KI

Was es ist. Eine einheitliche API, die LLMs + Bildgenerierung + OCR/Dokumentenverarbeitung + Sprache + Übersetzung, umfasst und die Notwendigkeit beseitigt, mehrere Anbieter-SDKs zu kombinieren. Modellvergleich hilft Ihnen, Anbieter nebeneinander zu testen. Es betont auch Kosten-/API-Überwachung, Stapelverarbeitung, und Caching.
Gute Passform, wenn. Ihre Roadmap ist multimodal und Sie möchten OCR/Sprache/Übersetzung zusammen mit LLM-Chat von einer einzigen Oberfläche aus orchestrieren.
Vorsicht. Wenn Sie ein Marktplatzansicht pro Anfrage (Preis/Latenzzeit/Betriebszeit/Verfügbarkeit) oder Anbieterökonomie auf Ebene, ziehen Sie einen marktplatzartigen Router wie TeilenAI zusammen mit Edens multimodalen Funktionen in Betracht.
OpenRouter

Was es ist. Ein einheitlicher LLM-Router mit Anbieter-/Modell-Routing und Prompt-Caching. Wenn das Caching aktiviert ist, versucht OpenRouter, Sie beim gleichen Anbieter zu halten, um warme Kontexte wiederzuverwenden; wenn dieser Anbieter nicht verfügbar ist, wechselt es zum nächstbesten.
Gute Passform, wenn. Sie möchten gehostete Geschwindigkeit und cache-bewusstes Routing um Kosten zu senken und den Durchsatz zu verbessern – insbesondere bei hochfrequenten Chat-Arbeitslasten mit wiederholten Eingabeaufforderungen.
Vorsicht. Für tiefgehende Unternehmenssteuerung (z. B. SIEM-Exporte, organisationsweite Richtlinie), viele Teams OpenRouter mit Portkey oder Kong AI Gateway koppeln.
Portkey

Was es ist. Eine KI Betriebsplattform + Gateway mit programmierbarem Fallbacks, Ratenbegrenzungs-Playbooks, und einfacher/semantischer Cache, plus Traces/Metriken für SRE-ähnliche Kontrolle.
- Verschachtelte Fallbacks & bedingtes Routing — Wiederholungsbäume ausdrücken (z. B. 429er wiederholen; bei 5xx umschalten; bei Latenzspitzen umschalten).
- Semantischer Cache — gewinnt oft bei kurzen Eingaben/Nachrichten (Einschränkungen gelten).
- Virtuelle Schlüssel/Budgets — halten Sie die Team-/Projektverwendung in der Richtlinie.
Gute Passform, wenn. Sie benötigen richtliniengesteuertes Routing mit erstklassiger Beobachtbarkeit, und Sie sind vertraut mit dem Betrieb eines Gateway Schicht vor einem oder mehreren Routern/Marktplätzen.
Kong KI-Gateway

Was es ist. Eine Edge-Gateway das bringt KI-Plugins, Governance und Analysen in das Kong-Ökosystem (über Konnect oder selbstverwaltet). Es ist Infrastruktur – eine starke Lösung, wenn Ihre API-Plattform bereits auf Kong basiert und Sie zentrale Richtlinien/Audits.
Gute Passform, wenn. Edge-Governance, Prüfungsfähigkeit, Datenresidenz, und zentrale Steuerungen in Ihrer Umgebung unverzichtbar sind.
Vorsicht. Erwarten Sie Einrichtung und Wartung. Viele Teams kombinieren Kong mit einem Marktplatz-Router (z. B. ShareAI/OpenRouter) für die Anbieterwahl und Kostenkontrolle.
Vereinheitlichen

Was es ist. A datengetriebener Router das optimiert für Kosten/Geschwindigkeit/Qualität unter Verwendung Live-Benchmarks. Es stellt eine universelle API bereit und aktualisiert Modelloptionen nach Region/Arbeitslast.
Gute Passform, wenn. Sie möchten benchmark-gesteuerte Auswahl die sich kontinuierlich an die reale Leistung anpasst.
Orq.ai

Was es ist. Eine generative KI Zusammenarbeit + LLMOps Plattform: Experimente, Evaluatoren (einschließlich RAG Metriken wie Kontextrelevanz/Genauigkeit/Robustheit), Bereitstellungen und RBAC/VPC.
Gute Passform, wenn. Sie benötigen Experimentieren + Evaluieren mit Governance an einem Ort – und dann direkt von derselben Oberfläche bereitstellen.
LiteLLM

Was es ist. Eine Open-Source-Proxy/Gateway mit OpenAI-kompatibel Endpunkte, Budgets & Ratenlimits, Protokollierung/Metriken und eine Admin-Benutzeroberfläche. Bereitstellung über Docker/K8s/Helm; halten Sie den Datenverkehr in Ihrem eigenen Netzwerk.
Gute Passform, wenn. Sie möchten Selbsthosting und vollständige Infrastrukturkontrolle mit einfacher Kompatibilität für beliebte OpenAI-ähnliche SDKs.
Vorsicht. Wie bei jedem OSS-Gateway, verwalten Sie Betrieb und Upgrades selbst. Stellen Sie sicher, dass Sie Zeit für Überwachung, Skalierung und Sicherheitsupdates einplanen.
Schnellstart: Modell in Minuten aufrufen (ShareAI)
Starten Sie in der Spielplatz, holen Sie sich dann einen API-Schlüssel und starten Sie. Referenz: API-Schnellstart • Docs Startseite • Veröffentlichungen.
#!/usr/bin/env bash"
// ShareAI — Chat-Abschlüsse (JavaScript, Node 18+);
Migrationstipp: Ordnen Sie Ihre aktuellen Requesty-Modelle den ShareAI-Äquivalenten zu, spiegeln Sie Anfrage-/Antwortstrukturen und starten Sie hinter einer Feature-Flag. Senden Sie zunächst 5–10% des Traffics, vergleichen Sie Latenz/Kosten/Qualität, und erhöhen Sie dann. Wenn Sie auch ein Gateway (Portkey/Kong) betreiben, stellen Sie sicher, dass Caching/Fallbacks nicht doppelt über Schichten ausgelöst werden.
Vergleich auf einen Blick
| Plattform | Gehostet / Selbst-Hosting | Routing & Fallbacks | Beobachtbarkeit | Breite (LLM + darüber hinaus) | Governance/Richtlinien | Notizen |
|---|---|---|---|---|---|---|
| Anfrage | Gehostet | Router mit Failover; OpenAI-kompatibel | Eingebaute Überwachung/Analytik | LLM-zentriert (Chat/Abschlüsse) | Governance auf Organisationsebene | Ersetzen Sie die OpenAI-Basis-URL durch Requesty; Schwerpunkt auf Unternehmen. |
| TeilenAI | Gehostet + Providernetzwerk | Sofortiges Failover; marktplatzgesteuerte Weiterleitung hinzu | Nutzungsprotokolle; Marktplatzstatistiken | Breiter Modellkatalog | Anbieterbezogene Steuerungen | Menschenbetriebener Marktplatz; beginnen Sie mit dem Spielplatz. |
| Eden KI | Gehostet | Anbieter wechseln; Batch; Caching | Kosten- und API-Überwachung | LLM + Bild + OCR + Sprache + Übersetzung | Zentrale Abrechnung/Schlüsselverwaltung | Modellvergleich, um Anbieter nebeneinander zu testen. |
| OpenRouter | Gehostet | Anbieter-/Modell-Routing; Prompt-Caching | Anforderungsbezogene Informationen | LLM-zentriert | Anbieter-Richtlinien | Cache-Wiederverwendung, wo unterstützt; Fallback bei Nichtverfügbarkeit. |
| Portkey | Gehostet & Gateway | Richtlinien-Fallbacks; Rate-Limit-Playbooks; Semantischer Cache | Traces/Metriken | LLM-zuerst | Gateway-Konfigurationen | Großartig für SRE-ähnliche Leitplanken und Organisationsrichtlinien. |
| Kong KI-Gateway | Selbst-Hosting/Unternehmen | Upstream-Routing über AI-Plugins | Metriken/Audit über Kong | LLM-zuerst | Starke Edge-Governance | Infrastrukturkomponente; kombiniert mit einem Router/Marktplatz. |
| Vereinheitlichen | Gehostet | Datengetriebenes Routing nach Kosten/Geschwindigkeit/Qualität | Benchmark-Explorer | LLM-zentriert | Router-Präferenzen | Benchmark-gesteuerte Modellauswahl. |
| Orq.ai | Gehostet | Wiederholungen/Fallbacks in der Orchestrierung | Plattformanalysen; RAG-Bewerter | LLM + RAG + Bewertungen | RBAC/VPC-Optionen | Fokus auf Zusammenarbeit & Experimentieren. |
| LiteLLM | Selbst-Hosting/OSS | Wiederholen/Fallback; Budgets/Limits | Protokollierung/Metriken; Admin-UI | LLM-zentriert | Volle Infrastrukturkontrolle | OpenAI-kompatibel; Docker/K8s/Helm-Bereitstellung. |
FAQs
Was ist Requesty?
Ein LLM Gateway bietet Multi-Provider-Routing über eine einzige OpenAI-kompatible API mit Überwachung, Governance und Kostenkontrolle.
Was sind die besten Alternativen zu Requesty?
Top-Auswahlen umfassen TeilenAI (Marktplatztransparenz + sofortiges Failover), Eden KI (multimodale API + Modellvergleich), OpenRouter (cache-bewusstes Routing), Portkey (Gateway mit Richtlinien & semantischem Cache), Kong KI-Gateway (Edge-Governance), Vereinheitlichen (datengetriebener Router), Orq.ai (LLMOps/Evaluatoren), und LiteLLM (selbstgehosteter Proxy).
Requesty vs ShareAI — welches ist besser?
Wählen TeilenAI wenn Sie möchten, dass transparenter Marktplatz das Preis/Latenzzeit/Betriebszeit/Verfügbarkeit, bevor Sie routen, plus sofortiges Failover und entwicklerorientierte Wirtschaftlichkeit. Wählen Anfrage wenn Sie ein einziges gehostetes Gateway mit Unternehmensführung bevorzugen und sich wohl fühlen, Anbieter ohne Marktplatzansicht auszuwählen. Probieren Sie ShareAI’s Modell-Marktplatz und Spielplatz.
Requesty vs Eden AI — was ist der Unterschied?
Eden KI umfasst LLMs + multimodal (Vision/OCR, Sprache, Übersetzung) und beinhaltet Modellvergleich; Anfrage ist mehr LLM-zentriert mit Routing/Governance. Wenn Ihre Roadmap OCR/Sprache/Übersetzung unter einer API benötigt, vereinfacht Eden AI die Bereitstellung; für Gateway-Style-Routing passt Requesty.
Requesty vs OpenRouter — wann sollte man welches wählen?
Wählen OpenRouter wann Prompt-Caching und Warm-Cache-Wiederverwendung Angelegenheit (es neigt dazu, Sie beim selben Anbieter zu halten und fällt bei Ausfällen zurück). Wählen Anfrage für Unternehmenssteuerung mit einem einzelnen Router und wenn Cache-bewusste Anbieterbindung nicht Ihre oberste Priorität ist.
Requesty vs Portkey vs Kong AI Gateway — Router oder Gateway?
Anfrage ist ein Router. Portkey und Kong KI-Gateway sind Gateways: sie glänzen bei Richtlinien/Leitplanken (Fallbacks, Ratenbegrenzungen, Analysen, Edge-Governance). Viele Stacks verwenden sowohl: ein Gateway für organisationsweite Richtlinien + einen Router/Marktplatz für Modellauswahl und Kostenkontrolle.
Requesty vs Unify — was ist einzigartig an Unify?
Vereinheitlichen verwendet Live-Benchmarks und dynamische Richtlinien, um Kosten/Geschwindigkeit/Qualität zu optimieren. Wenn Sie datengetriebenes Routing die sich je nach Region/Arbeitslast entwickelt, Unify ist überzeugend; Requesty konzentriert sich auf Gateway-Style-Routing und Governance.
Requesty vs Orq.ai — welches für Evaluierung & RAG?
Orq.ai bietet ein Experimentieren/Evaluieren Oberfläche (einschließlich RAG-Evaluatoren), plus Deployments und RBAC/VPC. Wenn Sie benötigen LLMOps + Evaluatoren, kann Orq.ai in frühen Phasen einen Router ergänzen oder ersetzen.
Requesty vs LiteLLM — gehostet vs selbstgehostet?
Anfrage ist gehostet. LiteLLM ist ein selbstgehosteter Proxy/Gateway mit Budgets & Rate-Limits und eine Admin-UI; großartig, wenn Sie den Traffic innerhalb Ihres VPC halten und die Steuerungsebene besitzen möchten.
Was ist am günstigsten für meine Arbeitslast: Requesty, ShareAI, OpenRouter, LiteLLM?
Es hängt ab von Modellwahl, Region, Cachebarkeit und Verkehrsmuster. Router wie ShareAI/OpenRouter können Kosten durch Routing und cache-bewusste Stickiness reduzieren; Gateways wie Portkey fügen semantisches Caching; LiteLLM reduzieren den Plattform-Overhead, wenn Sie sich mit dem Betrieb wohlfühlen. Benchmarken Sie mit Ihren Eingaben und verfolgen Sie die effektiven Kosten pro Ergebnis—nicht nur den Listenpreis.
Wie migriere ich von Requesty zu ShareAI mit minimalen Codeänderungen?
Ordnen Sie Ihre Modelle den ShareAI-Äquivalenten zu, spiegeln Sie die Anfrage-/Antwortstrukturen und starten Sie hinter einem Feature-Flag. Routen Sie zuerst ein kleines %, vergleichen Sie Latenz/Kosten/Qualität und skalieren Sie dann. Wenn Sie auch ein Gateway betreiben, stellen Sie sicher, dass Caching/Fallbacks keine doppelten Trigger zwischen den Schichten auftreten.
Deckt dieser Artikel auch “Requestly-Alternativen” ab? (Requesty vs Requestly)
Ja—Requestly (mit einem L) ist eine Entwickler-/QA-Tool-Suite (HTTP-Abfangung, API-Mocking/Testing, Regeln, Header) anstelle eines LLM-Routers. Wenn Sie nach Requestly-Alternativen, gesucht haben, vergleichen Sie wahrscheinlich Postman, Fiddler, mitmproxy, usw. Wenn Sie Anfrage (LLM-Gateway) meinten, verwenden Sie die Alternativen in diesem Leitfaden. Wenn Sie live chatten möchten, buchen Sie ein Meeting: meet.growably.ro/team/shareai.
Was ist der schnellste Weg, ShareAI ohne vollständige Integration auszuprobieren?
Öffnen Sie die Spielplatz, wählen Sie ein Modell/Anbieter aus und führen Sie Eingabeaufforderungen im Browser aus. Wenn Sie bereit sind, erstellen Sie einen Schlüssel im Konsole und fügen Sie die cURL/JS-Snippets in Ihre App ein.
Kann ich ein ShareAI-Anbieter werden und verdienen?
Ja. Jeder kann sich als Gemeinschaft oder Unternehmen Anbieter registrieren, indem er Windows/Ubuntu/macOS oder Docker. Beitragen Leerlaufzeit-Ausbrüche oder ausführen immer eingeschaltet. verwendet. Wählen Sie Belohnungen (Geld), Austausch (Tokens/AI Prosumer), oder Mission (spenden Sie % an NGOs). Siehe die Anbieterleitfaden.
Gibt es eine einzige “beste” Alternative zu Requesty?
Kein einzelner Gewinner für jedes Team. Wenn Sie Wert auf Marktplatztransparenz + sofortiges Failover + Builder-Ökonomie, legen, beginnen Sie mit TeilenAI. 3. . Für multimodal Arbeitslasten (OCR/Sprache/Übersetzung), schauen Sie sich Eden KI. Wenn Sie Edge-Governance, bewerten Portkey oder Kong KI-Gateway. Bevorzugen Selbsthosting? Erwägen LiteLLM.
Fazit
Während Anfrage ist ein starkes LLM-Gateway, hängt Ihre beste Wahl von den Prioritäten ab:
- Marktplatztransparenz + Resilienz: TeilenAI
- Multimodale Abdeckung unter einer API: Eden KI
- Cache-bewusstes Routing in gehosteter Form: OpenRouter
- Richtlinien/Leitplanken am Edge: Portkey oder Kong KI-Gateway
- Datengetriebenes Routing: Vereinheitlichen
- LLMOps + Evaluatoren: Orq.ai
- Selbstgehostete Steuerungsebene: LiteLLM
Wenn Sie Anbieter auswählen nach Preis/Latenzzeit/Betriebszeit/Verfügbarkeit vor jeder Route, sofortiges Failover, und wirtschaftliche Ausrichtung auf den Ersteller stehen auf Ihrer Checkliste, öffnen Sie die Spielplatz, erstellen Sie einen API-Schlüssel, und durchsuchen Sie die Modell-Marktplatz , um Ihre nächste Anfrage auf intelligente Weise zu leiten.

