
EmbeddingGemma ist jetzt auf ShareAI verfügbar
Wir kündigen an, dass EinbettungGemma, Googles kompaktes Open-Embedding-Modell, jetzt auf ShareAI verfügbar ist.
Mit 300 Millionen Parametern, liefert EmbeddingGemma eine erstklassige Leistung für seine Größe. Es basiert auf Gemma 3 mit T5Gemma-Initialisierung und verwendet dieselbe Forschung und Technologie wie die Zwilling Modelle. Das Modell erzeugt Vektordarstellungen von Text und ist damit ideal für Such- und Abrufaufgaben geeignet, einschließlich Klassifikation, Clustering, und semantische Ähnlichkeit. Es wurde mit Daten in 100+ gesprochenen Sprachen.
Warum es wichtig ist
Die kleine Größe des Modells und der Fokus auf Geräte machen es praktisch, in Umgebungen mit begrenzten Ressourcen eingesetzt zu werden—Mobiltelefone, Laptops oder Desktops—demokratisiert den Zugang zu hochmodernen KI-Modellen und fördert Innovationen für alle.
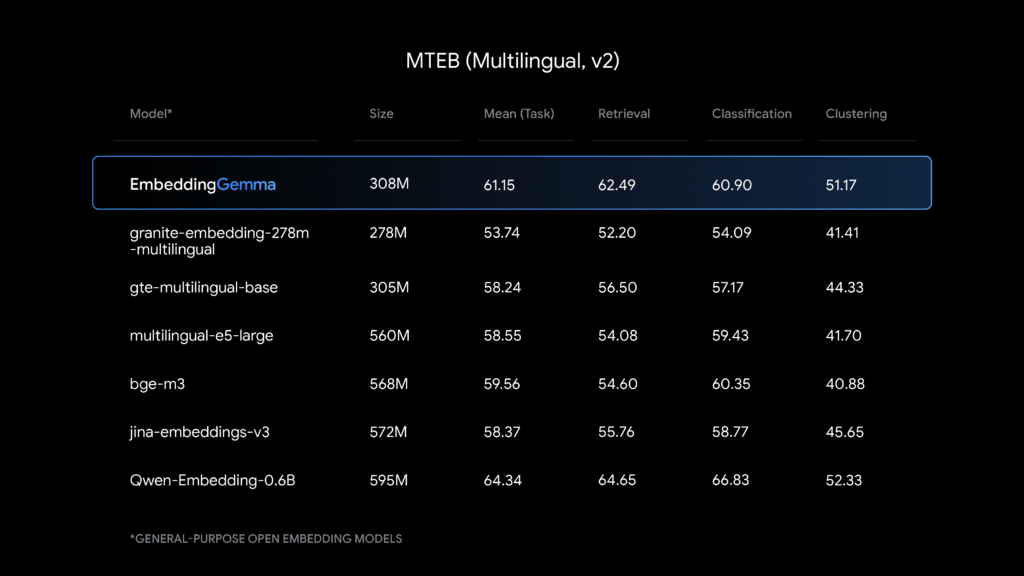
Benchmark
Trainingsdatensatz
EmbeddingGemma wurde mit Daten in 100+ gesprochenen Sprachen trainiert.
- Web-Dokumente
Eine vielfältige Sammlung von Webtexten sorgt für eine breite sprachliche Vielfalt, Themen und Vokabular. Der Datensatz enthält Inhalte in 100+ Sprachen. - Code und technische Dokumente
Die Einbeziehung von Programmiersprachen und spezialisiertem wissenschaftlichem Inhalt hilft dem Modell, Strukturen und Muster zu lernen, die das Verständnis von Code und technischen Fragen verbessern. - Synthetische und aufgabenbezogene Daten
Kuratierte synthetische Daten vermitteln spezifische Fähigkeiten für Informationsabruf, Klassifikation und Sentiment-Analyse und optimieren die Leistung für gängige Einbettungsanwendungen.
Diese Kombination aus vielfältigen Quellen ist entscheidend für ein leistungsstarkes mehrsprachiges Einbettungsmodell, das eine breite Palette von Aufgaben und Datenformaten bewältigen kann.
Was Sie bauen können
Verwenden Sie EmbeddingGemma für Suche und Abruf, semantische Ähnlichkeit, Klassifikations-Pipelines, und Clustering—besonders wenn Sie hochwertige Einbettungen benötigen, die auf eingeschränkten Geräten laufen können.
Referenz
Jetzt verfügbar auf ShareAI.
Führen Sie es aus. Testen Sie es. Liefern Sie es aus.

