
EmbeddingGemma saiki ana ing ShareAI
Kita ngumumake yen EmbeddingGemma, model embedding kompak saka Google, saiki kasedhiya ing ShareAI.
Ing 300 yuta parameter, EmbeddingGemma menehi kinerja paling apik kanggo ukurané. Iki dibangun saka Gemma 3 kanthi T5Gemma inisialisasi lan nggunakake riset lan teknologi sing padha ing balik Gemini model. Model iki ngasilake representasi vektor saka teks, nggawe cocok kanggo tugas telusuran lan pengambilan, kalebu klasifikasi, klustering, lan kesamaan semantik. Iki dilatih nganggo data ing 100+ basa sing diucapaké.
Napa iki penting
Ukuran model sing cilik lan fokus ing piranti nggawe praktis kanggo digunakaké ing lingkungan kanthi sumber daya sing winates—telpon seluler, laptop, utawa desktop—demokratisasi akses menyang model AI paling anyar lan nyengkuyung inovasi kanggo kabeh wong.
Patokan
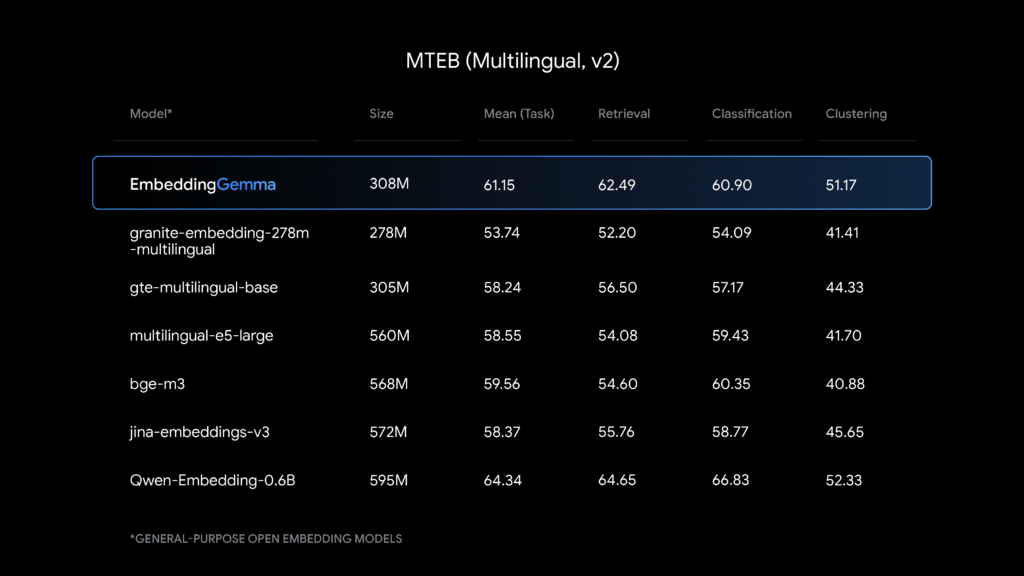
Dataset pelatihan
EmbeddingGemma dilatih nganggo data ing 100+ basa sing diucapaké.
- Dokumen web
Koleksi teks web sing beragam njamin paparan gaya linguistik, topik, lan kosakata sing luas. Dataset iki kalebu konten ing 100+ basa. - Kode lan dokumen teknis
Kalebu basa pemrograman lan konten ilmiah khusus mbantu model sinau struktur lan pola sing ningkataké pangerten kode lan pitakon teknis. - Data sintetik lan tugas khusus
Data sintetik sing dikurasi ngajari katrampilan khusus kanggo pengambilan informasi, klasifikasi, lan analisis sentimen, nyetel kinerja kanggo aplikasi embedding umum.
Kombinasi saka sumber sing maneka warna iki penting kanggo model embedding multibasa sing kuat sing bisa nangani macem-macem tugas lan format data.
Apa sing bisa sampeyan bangun
Gunakake EmbeddingGemma kanggo panelusuran lan pangambilan, kesamaan semantik, pipeline klasifikasi, lan klustering—utamane nalika sampeyan butuh embedding kualitas dhuwur sing bisa mlaku ing piranti sing diwatesi.
Referensi
Saiki kasedhiya ing ShareAI.
Lakokna. Coba. Kirim.

