
EmbeddingGemma가 이제 ShareAI에서 사용할 수 있습니다.
우리는 발표합니다. 임베딩젬마, Google의 컴팩트한 오픈 임베딩 모델이 이제 ShareAI에서 사용할 수 있습니다.
매개변수 3억 개, 에서, EmbeddingGemma는 크기에 비해 최첨단 성능을 제공합니다. 이는 젬마 3 와 함께 T5Gemma 초기화 를 기반으로 구축되었으며, 제미니 모델 뒤에 있는 동일한 연구와 기술을 사용합니다. 이 모델은 텍스트의 벡터 표현을 생성하여 검색 및 검색 작업에 적합하며, 분류, 클러스터링, 그리고 의미적 유사성을 포함합니다.. 데이터로 훈련되었습니다 100개 이상의 구어 언어.
왜 중요한가
모델의 작은 크기와 기기 내 초점은 제한된 자원을 가진 환경에서 배포를 실용적으로 만듭니다—모바일 폰, 노트북, 또는 데스크톱—최첨단 AI 모델에 대한 접근을 민주화하고 모두를 위한 혁신을 촉진합니다.
벤치마크
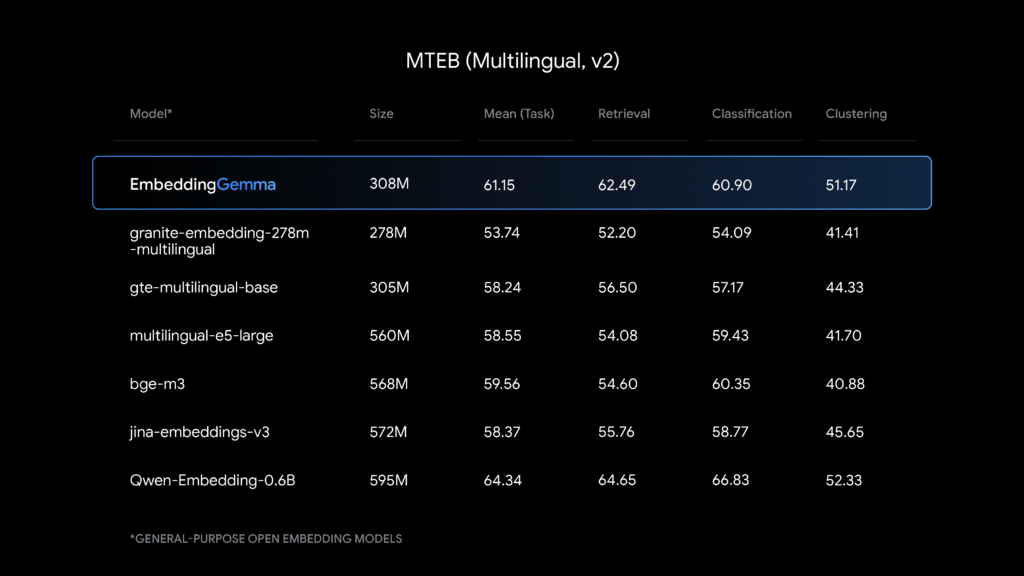
훈련 데이터셋
EmbeddingGemma는 100개 이상의 구어 언어로 데이터를 훈련받았습니다.
- 웹 문서
다양한 웹 텍스트 컬렉션은 폭넓은 언어 스타일, 주제 및 어휘에 노출되도록 보장합니다. 데이터셋에는 100개 이상의 언어로 된 콘텐츠가 포함됩니다.. - 코드 및 기술 문서
프로그래밍 언어와 전문 과학 콘텐츠를 포함하여 모델이 코드와 기술 질문의 이해를 향상시키는 구조와 패턴을 학습하도록 돕습니다. - 합성 및 작업별 데이터
큐레이션된 합성 데이터는 정보 검색, 분류 및 감정 분석을 위한 특정 기술을 가르치며, 일반적인 임베딩 응용 프로그램의 성능을 미세 조정합니다.
다양한 소스의 조합은 다양한 작업과 데이터 형식을 처리할 수 있는 강력한 다국어 임베딩 모델에 필수적입니다.
당신이 구축할 수 있는 것
EmbeddingGemma를 사용하여 검색 및 검색, 의미적 유사성을 포함합니다., 분류 파이프라인, 그리고 클러스터링—특히 제한된 장치에서 실행할 수 있는 고품질 임베딩이 필요할 때.
참고
ShareAI에서 지금 이용 가능합니다.
실행하세요. 테스트하세요. 배포하세요.

