
O ShareAI está comprometido em trazer para você os modelos de IA mais recentes e poderosos—e estamos fazendo isso novamente hoje.
Horas atrás, OpenAI lançou seu inovador GPT-OSS modelos, e você já pode começar a usá-los na rede ShareAI!
Os modelos recém-lançados—gpt-oss:20b and gpt-oss:120b—oferecem experiências de chat local excepcionais, capacidades de raciocínio poderosas e suporte aprimorado para cenários avançados de desenvolvedores.
🚀 Comece com o GPT-OSS no ShareAI
Você pode experimentar esses modelos agora mesmo usando a versão mais recente do cliente Windows do ShareAI.
- Baixe o ShareAI para Windows (link para a página de download)
Após a instalação, você pode facilmente baixar e executar os modelos GPT-OSS diretamente do aplicativo ShareAI—sem configurações ou instalações complicadas necessárias.
✨ Destaques de Recursos do GPT-OSS
Aqui está o motivo pelo qual o GPT-OSS é revolucionário para seus fluxos de trabalho orientados por IA:
- Capacidades Agentes:
Aproveite os recursos integrados para chamadas de função, navegação na web, chamadas de ferramentas Python e saídas de dados estruturados. - Transparência completa na cadeia de pensamento:
Obtenha visibilidade clara no processo de raciocínio do modelo, permitindo depuração mais fácil e maior confiança nos resultados gerados. - Níveis de raciocínio configuráveis:
Ajuste facilmente o esforço de raciocínio (baixo, médio, alto) com base nas suas necessidades de latência e complexidade. - Arquitetura ajustável:
Personalize extensivamente os modelos com ajuste de parâmetros para casos de uso específicos. - Licença permissiva Apache 2.0:
Inove livremente sem licenças copyleft restritivas ou riscos de patentes—perfeito para implantação comercial e experimentação rápida.
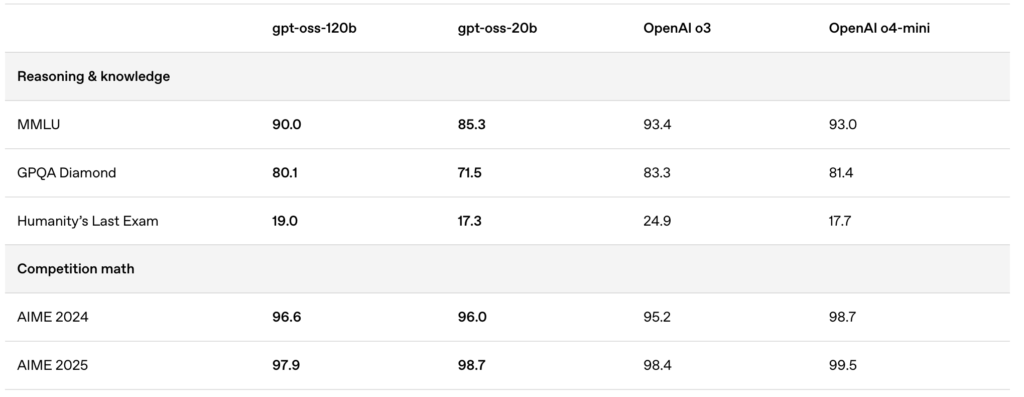
🔥 Otimizado com Quantização MXFP4
A OpenAI introduziu a quantização MXFP4, reduzindo significativamente o uso de memória dos modelos GPT-OSS:
- Formato MXFP4 Explicado:
Os modelos GPT-OSS utilizam uma técnica de quantização onde os pesos Mixture-of-Experts (MoE) são quantizados para apenas 4,25 bits por parâmetro. Esses pesos MoE compreendem mais de 90% dos parâmetros totais do modelo, tornando a quantização incrivelmente eficiente. - Compatibilidade Aprimorada:
Esta quantização otimizada permite:- The gpt-oss:20b modelo rodar suavemente em máquinas com apenas 16GB de memória.
- The gpt-oss:120b modelo se ajustar confortavelmente em uma única GPU de 80GB.
ShareAI suporta este formato MXFP4 nativamente—sem etapas extras, conversões ou complicações necessárias. Nossa última atualização de engine vem com kernels recém-desenvolvidos especificamente projetados para o formato MXFP4, garantindo desempenho máximo.
📌 Modelos GPT-OSS Disponíveis Agora:
GPT-OSS:20B
- Ideal para tarefas especializadas de baixa latência ou implementações locais.
- Oferece desempenho robusto mesmo em configurações de hardware modestas.
GPT-OSS:120B
- Oferece raciocínio poderoso, capacidades avançadas de agência e versatilidade adequadas para tarefas exigentes em grande escala.
- Perfeito para desenvolvedores e empresas que necessitam de raciocínio mais profundo, maior precisão e aplicações de IA mais amplas.
🛠️ Experimente o GPT-OSS hoje
Pronto para experimentar capacidades de IA de próxima geração?
- Baixe o Cliente Windows do ShareAI (link para a página de download)
- Ver Documentação (link para documentos do usuário ou tutoriais)
Fique ligado—o ShareAI continua a expandir nossa biblioteca de modelos, capacitando seus projetos de IA em cada etapa do caminho.
Boas solicitações! 🚀

