
EmbeddingGemma ఇప్పుడు ShareAI లో ఉంది
మేము ప్రకటిస్తున్నాము ఎంబెడింగ్ జెమ్మా, Google యొక్క కాంపాక్ట్ ఓపెన్ ఎంబెడింగ్ మోడల్, ఇప్పుడు ShareAI లో అందుబాటులో ఉంది.
వద్ద 300 మిలియన్ పరామితులు, EmbeddingGemma దాని పరిమాణానికి అత్యాధునిక పనితీరును అందిస్తుంది. ఇది జెమ్మా 3 తో T5Gemma ప్రారంభీకరణ మరియు జెమినీ మోడల్స్ వెనుక ఉన్న అదే పరిశోధన మరియు సాంకేతికతను ఉపయోగిస్తుంది. ఈ మోడల్ టెక్స్ట్ యొక్క వెక్టర్ ప్రాతినిధ్యాలను ఉత్పత్తి చేస్తుంది, ఇది శోధన మరియు రిట్రీవల్ పనులకు అనుకూలంగా ఉంటుంది, అందులో వర్గీకరణ, క్లస్టరింగ్, మరియు సేమాంటిక్ సిమిలారిటీ. ఇది డేటాతో శిక్షణ పొందింది 100+ మాట్లాడే భాషలు.
ఎందుకు ఇది ముఖ్యమైంది
మోడల్ యొక్క చిన్న పరిమాణం మరియు ఆన్-డివైస్ ఫోకస్ పరిమిత వనరులతో ఉన్న వాతావరణాలలో అమలు చేయడానికి అనువుగా చేస్తుంది—మొబైల్ ఫోన్లు, ల్యాప్టాప్లు, లేదా డెస్క్టాప్లు—అత్యాధునిక AI మోడళ్లకు ప్రాప్యతను ప్రజాస్వామ్యపరచడం మరియు అందరికీ ఆవిష్కరణను ప్రోత్సహించడం.
బెంచ్మార్క్
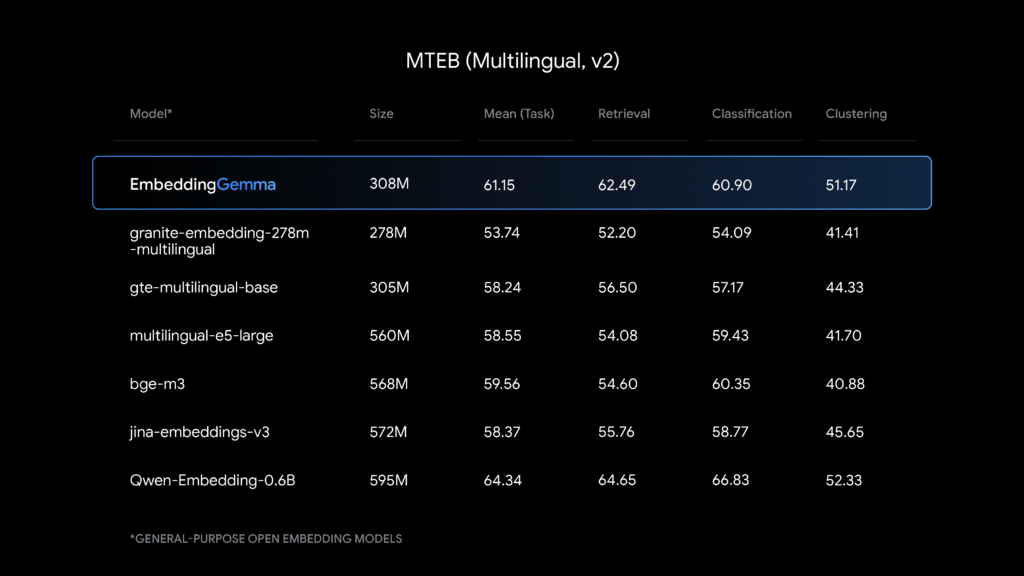
శిక్షణ డేటాసెట్
EmbeddingGemma 100+ మాట్లాడే భాషలలో డేటాతో శిక్షణ పొందింది.
- వెబ్ డాక్యుమెంట్లు
వెబ్ టెక్స్ట్ యొక్క విభిన్న సేకరణ విస్తృత భాషా శైలులు, విషయాలు, మరియు పదజాలానికి ప్రాప్యతను నిర్ధారిస్తుంది. డేటాసెట్లో కంటెంట్ ఉంది 100+ భాషలు. - కోడ్ మరియు సాంకేతిక డాక్యుమెంట్లు
ప్రోగ్రామింగ్ భాషలు మరియు ప్రత్యేక శాస్త్రీయ కంటెంట్ను చేర్చడం మోడల్కు కోడ్ మరియు సాంకేతిక ప్రశ్నల యొక్క అవగాహనను మెరుగుపరచే నిర్మాణం మరియు నమూనాలను నేర్చుకోవడంలో సహాయపడుతుంది. - సింథటిక్ మరియు టాస్క్-స్పెసిఫిక్ డేటా
క్యూరేటెడ్ సింథటిక్ డేటా సమాచారం రిట్రీవల్, వర్గీకరణ, మరియు భావ విశ్లేషణ కోసం ప్రత్యేక నైపుణ్యాలను నేర్పుతుంది, సాధారణ ఎంబెడింగ్ అప్లికేషన్ల కోసం పనితీరును మెరుగుపరుస్తుంది.
విభిన్న వనరుల కలయిక విస్తృత శ్రేణి పనులు మరియు డేటా ఫార్మాట్లను నిర్వహించగల శక్తివంతమైన బహుభాషా ఎంబెడింగ్ మోడల్ కోసం కీలకమైనది.
మీరు నిర్మించగలిగేది
EmbeddingGemma ఉపయోగించండి శోధన మరియు రిట్రీవల్, సేమాంటిక్ సిమిలారిటీ, వర్గీకరణ పైప్లైన్లు, మరియు క్లస్టరింగ్—ప్రత్యేకంగా మీరు పరిమిత పరికరాలపై నడిచే అధిక-నాణ్యత ఎంబెడింగ్లను అవసరం ఉన్నప్పుడు.
సూచన
ShareAI లో ఇప్పుడు అందుబాటులో ఉంది.
దీన్ని నడపండి. పరీక్షించండి. పంపండి.

