
Ang EmbeddingGemma ay nasa ShareAI na
Inanunsyo namin na Pag-embedGemma, ang compact open embedding model ng Google, ay available na sa ShareAI.
Sa 300 milyong mga parameter, ang EmbeddingGemma ay naghahatid ng state-of-the-art na performance para sa laki nito. Ito ay binuo mula sa Gemma 3 na may Inisyal na pagsisimula ng T5Gemma at gumagamit ng parehong pananaliksik at teknolohiya sa likod ng Gemini mga modelo. Ang modelo ay gumagawa ng vector representations ng teksto, na angkop para sa mga gawain ng paghahanap at pagkuha, kabilang ang klasipikasyon, pag-cluster, at semantikong pagkakatulad. Ito ay sinanay gamit ang data sa 100+ sinasalitang wika.
Bakit ito mahalaga
Ang maliit na sukat ng modelo at pokus sa device ay ginagawang praktikal itong i-deploy sa mga kapaligiran na may limitadong mapagkukunan—mga mobile phone, laptop, o desktop—demokratikong nagbibigay ng access sa mga makabagong AI model at nagpapalaganap ng inobasyon para sa lahat.
Benchmark
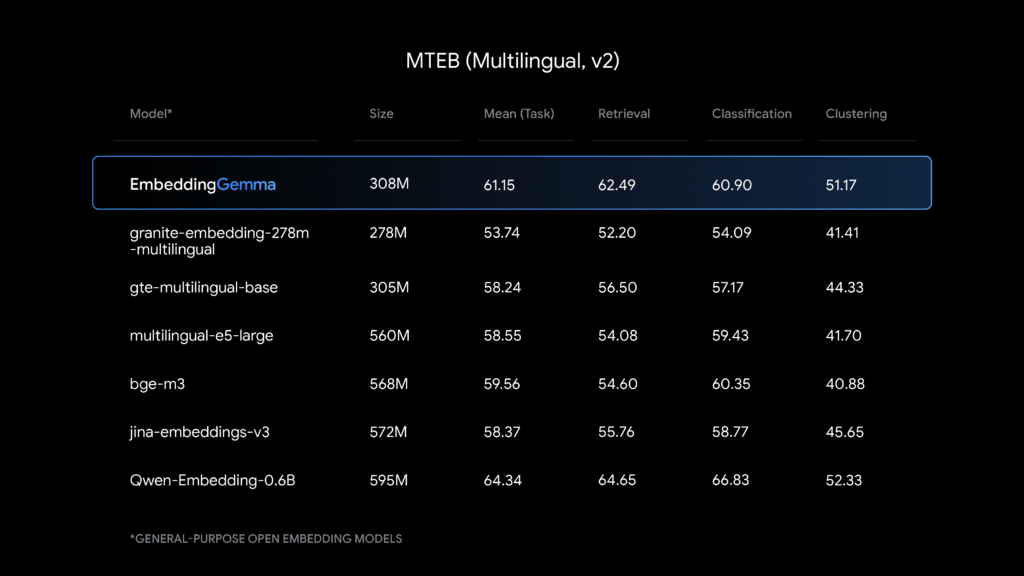
Dataset ng pagsasanay
Ang EmbeddingGemma ay sinanay gamit ang data sa 100+ sinasalitang wika.
- Mga dokumento sa web
Ang magkakaibang koleksyon ng web text ay nagsisiguro ng exposure sa malawak na istilo ng lingguwistika, mga paksa, at bokabularyo. Kasama sa dataset ang nilalaman sa 100+ wika. - Code at teknikal na mga dokumento
Kasama ang mga programming language at espesyal na siyentipikong nilalaman na tumutulong sa modelo na matutunan ang istruktura at mga pattern na nagpapabuti sa pag-unawa sa code at teknikal na mga tanong. - Synthetic at task-specific na data
Ang piniling synthetic na data ay nagtuturo ng mga partikular na kasanayan para sa pagkuha ng impormasyon, klasipikasyon, at pagsusuri ng damdamin, pinapahusay ang pagganap para sa mga karaniwang aplikasyon ng embedding.
Ang kombinasyon ng iba't ibang mga pinagmulan ay mahalaga para sa isang makapangyarihang multilingual embedding model na kayang hawakan ang malawak na hanay ng mga gawain at format ng data.
Ano ang maaari mong buuin
Gamitin ang EmbeddingGemma para sa paghahanap at pagkuha, semantikong pagkakatulad, mga klasipikasyon na pipeline, at pag-cluster—lalo na kapag kailangan mo ng mataas na kalidad na embeddings na maaaring tumakbo sa mga limitadong device.
Sanggunian
Available na ngayon sa ShareAI.
Patakbuhin ito. Subukan ito. Ipadala ito.

