
Na-update noong Marso 2026
Pinipili ng mga developer Requesty para sa isang solong, OpenAI-compatible na gateway sa maraming LLM providers kasama ang routing, analytics, at governance. Ngunit kung mas mahalaga sa iyo ang transparency ng marketplace bago ang bawat ruta (presyo, latency, uptime, availability), mahigpit na edge policy, o isang self-hosted na proxy, isa sa mga alternatibo sa Requesty ay maaaring mas angkop sa iyong stack.
Ang gabay na ito para sa mga mamimili ay isinulat tulad ng isang tagabuo: tiyak na mga trade-off, malinaw na mabilisang pagpili, malalim na pagsusuri, paghahambing sa tabi-tabi, at isang copy-paste IbahagiAI quickstart upang makapagpadala ka ngayon.
Pag-unawa sa Requesty (at kung saan maaaring hindi ito angkop)
Ano ang Requesty. Ang Requesty ay isang LLM tarangkahan. Itinuturo mo ang iyong OpenAI-compatible client sa isang Requesty endpoint at inaayos ang mga kahilingan sa iba't ibang provider/model—madalas na may failover, analytics, at mga patakaran sa seguridad. Isang lugar upang pamahalaan ang paggamit, subaybayan ang gastos, at ipatupad ang pamamahala sa iyong mga AI na tawag.
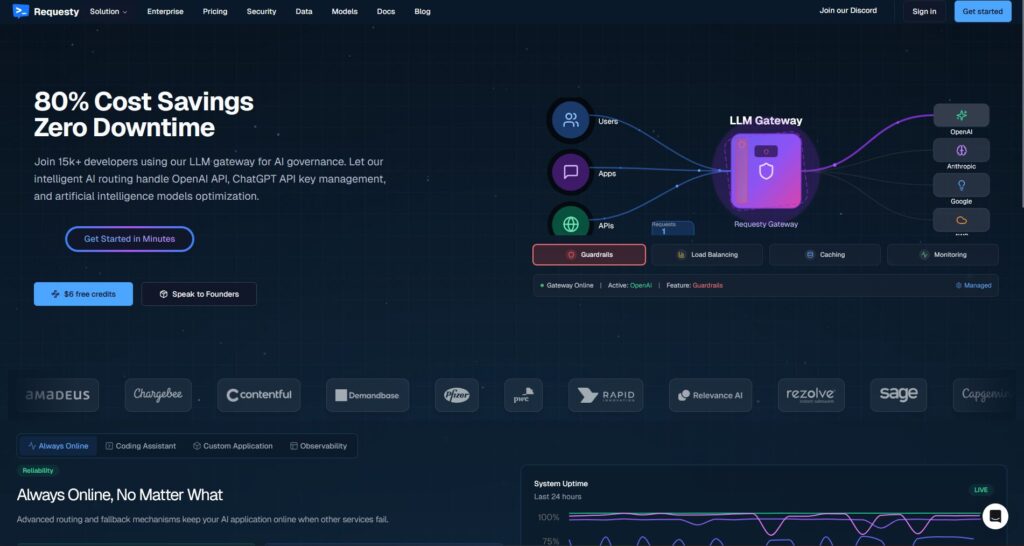
Bakit ito pinipili ng mga team.
- Isang API, maraming provider. Bawasan ang SDK sprawl at sentralisahin ang observability.
- Failover at routing. Panatilihing matatag ang uptime kahit na may problema ang isang provider.
- Pamamahala ng enterprise. Sentral na patakaran, kontrol sa antas ng organisasyon, mga badyet sa paggamit.
Kung saan maaaring hindi angkop ang Requesty.
- Gusto mo transparency ng marketplace bago ang bawat ruta (tingnan ang presyo, latency, uptime, availability per provider ngayon, pagkatapos pumili).
- Kailangan mo patakaran sa antas ng gilid sa iyong sariling stack (hal., Kong, Portkey) o sariling pagho-host (LiteLLM).
- Ang iyong roadmap ay nangangailangan malawak na multimodal mga tampok sa ilalim ng isang bubong (OCR, pagsasalita, pagsasalin, pag-parse ng dokumento) lampas sa LLM chat—kung saan ang isang tagapag-ayos tulad ng ShareAI ay maaaring mas angkop.
Paano pumili ng alternatibo sa Requesty
1) Kabuuang Gastos ng Pagmamay-ari (TCO). Huwag tumigil sa $/1K na mga token. Isama mga rate ng hit ng cache, mga retries/fallbacks, pag-queue, mga gastos sa evaluator, overhead bawat kahilingan, at ang pasanin ng ops ng observability/alerts. Ang “pinakamurang listahan ng presyo” ay madalas na natatalo sa isang router/gateway na nagpapababa ng basura.
2) Latency at pagiging maaasahan. Paboran routing na may kamalayan sa rehiyon, muling paggamit ng warm-cache (manatili sa parehong provider kapag aktibo ang prompt caching), at tumpak na fallbacks (subukang muli ang 429s; mag-escalate sa timeouts; limitahan ang fan-out upang maiwasan ang dobleng gastos).
3) Observability at pamamahala. Kung ang mga guardrails, audit logs, redaction, at patakaran sa gilid ay mahalaga, ang isang gateway tulad ng Portkey or Kong AI Gateway ay madalas na mas malakas kaysa sa isang purong aggregator. Maraming mga koponan ang nagpapareha ng router + gateway para sa pinakamahusay ng pareho.
4) Sariling host vs pinamamahalaan. Mas gusto ang Docker/K8s/Helm at mga endpoint na compatible sa OpenAI? Tingnan ang LiteLLM (OSS) o Kong AI Gateway (enterprise infra). Gusto ng bilis ng hosted + visibility ng marketplace? Tingnan ang IbahagiAI (ang aming pinili), OpenRouter, o Pag-isahin.
5) Lawak na lampas sa chat. Kung ang iyong roadmap ay may kasamang OCR, speech-to-text, pagsasalin, image gen, at doc parsing sa ilalim ng isang orchestrator, IbahagiAI maaaring gawing mas simple ang paghahatid at pagsubok.
6) Pagpaplano para sa hinaharap. Pumili ng mga tool na gumagawa ng pagpapalit ng modelo/provider na walang kahirap-hirap (universal APIs, dynamic routing, explicit model aliases), upang maaari kang magpatibay ng mas bago/mas mura/mas mabilis na mga opsyon nang walang muling pagsulat.
Pinakamahusay na mga alternatibo sa Requesty (mabilisang pagpili)
IbahagiAI (ang aming pagpili para sa transparency ng marketplace + ekonomiya ng tagabuo)
Isang API sa kabuuan 150+ na mga modelo na may instant failover at isang pamilihan na nagpapakita ng presyo, latency, uptime, availability bago ka mag-route. Ang mga provider (komunidad o kumpanya) ay nagpapanatili karamihan sa kita, pag-align ng mga insentibo sa pagiging maaasahan. Magsimula nang mabilis sa Palaruan, kunin ang mga susi sa Konsol, at basahin ang Mga Dokumento.
Eden AI (multimodal na tagapag-ayos)
Unified API sa iba't ibang LLMs kasama imahe, OCR/doc parsing, pagsasalita, at pagsasalin—kasama Paghahambing ng Modelo, pagmamanman, caching, at batch processing.
OpenRouter (routing na may kamalayan sa cache)
Hosted router sa iba't ibang LLMs na may pag-cache ng prompt at provider stickiness upang muling gamitin ang mga warm contexts; bumabagsak kapag ang isang provider ay nagiging hindi magagamit.
Portkey (policy & SRE ops sa gateway)
AI gateway na may mga programmable na fallback, rate-limit na mga playbook, at simple/semantic na cache, kasama ang detalyadong mga trace/metrics para sa kontrol ng produksyon.
Kong AI Gateway (pamamahala sa gilid at audit)
Dalhin AI plugins, polisiya, analytics sa Kong ecosystem; mahusay na ipares sa isang marketplace router kapag kailangan mo ng sentralisadong kontrol sa mga koponan.
Pag-isahin (data-driven na router)
Universal API na may live na benchmarks upang i-optimize ang gastos/bilis/kalidad ayon sa rehiyon at workload.
Orq.ai (eksperimentasyon at LLMOps)
Mga eksperimento, mga evaluator (kasama ang RAG metrics), mga deployment, RBAC/VPC—mahusay kapag kailangang magsama ang pagsusuri at pamamahala.
LiteLLM (self-hosted na proxy/gateway)
Open-source, OpenAI-compatible proxy na may mga budget/limitasyon, pag-log/pagsusukat, at isang Admin UI. I-deploy gamit ang Docker/K8s/Helm; ikaw ang may hawak ng operasyon.
Malalimang pagsusuri: mga nangungunang alternatibo
ShareAI (API ng AI na Pinapagana ng Tao)

Ano ito. Isang provider-first AI network at pinag-isang API. Mag-browse ng malaking katalogo ng mga modelo/provider at mag-route gamit ang agarang failover. Ang marketplace ay nagpapakita ng presyo, latency, uptime, at availability sa isang lugar upang ikaw ay makapili ng tamang provider bago ang bawat ruta. Magsimula sa Palaruan, lumikha ng mga key sa Konsol, at sundin ang Mabilis na pagsisimula ng API.
Bakit ito pinipili ng mga team.
- Transparency ng marketplace — tingnan ang provider presyo/latency/uptime/availability sa harapan.
- Katatagan-sa-default — mabilis failover sa susunod na pinakamahusay na provider kapag may isang aberya.
- Ekonomiya na nakahanay sa tagabuo — karamihan ng gastusin ay napupunta sa mga provider ng GPU na nagpapanatili ng mga modelo online.
- Walang hadlang na simula — Mag-browse ng Mga Modelo, subukan sa Palaruan, at ipadala.
Katotohanan ng provider (kumita sa pamamagitan ng pagpapanatili ng mga modelo online). Sinuman ay maaaring maging provider (Komunidad o Kumpanya). Sumali sa pamamagitan ng Windows/Ubuntu/macOS/Docker. Mag-ambag mga pagsabog sa idle-time o patakbuhin laging-naka-on. Pumili ng mga insentibo: Mga Gantimpala (pera), Palitan (mga token/AI Prosumer), o Misyon (mag-donate ng % sa mga NGO). Habang lumalaki ka, itakda ang iyong sariling mga presyo ng inference at makakuha ng mas pabor na exposure. Mga Detalye: Gabay sa Provider.
Perpekto para sa. Mga koponan ng produkto na nais transparency ng marketplace, katatagan, at ng espasyo para lumago sa mode ng provider—nang walang vendor lock-in.
Eden AI

Ano ito. Isang pinagsamang API na sumasaklaw sa LLMs + image gen + OCR/pagsusuri ng dokumento + pagsasalita + pagsasalin, inaalis ang pangangailangan na magtahi ng maraming vendor SDKs. Paghahambing ng Modelo tumutulong sa iyo na subukan ang mga provider nang magkatabi. Binibigyang-diin din nito Pagsubaybay sa Gastos/API, Pagproseso ng Batch, at Pag-cache.
Magandang akma kapag. Ang iyong roadmap ay multimodal at nais mong i-orchestrate ang OCR/pagsasalita/pagsasalin kasabay ng LLM chat mula sa isang solong surface.
Mga dapat bantayan. Kung kailangan mo ng tanawin ng marketplace bawat kahilingan (presyo/latency/uptime/availability) o ekonomiya sa antas ng provider, isaalang-alang ang isang router na estilo ng marketplace tulad ng IbahagiAI kasabay ng mga multimodal na tampok ng Eden.
OpenRouter

Ano ito. Isang pinag-isang LLM router na may pag-route ng provider/model at pag-cache ng prompt. Kapag naka-enable ang caching, sinusubukan ng OpenRouter na panatilihin ka sa parehong provider upang muling gamitin ang mga warm contexts; kung ang provider na iyon ay hindi magagamit, ito bumabagsak sa susunod na pinakamahusay.
Magandang akma kapag. Gusto mo bilis na naka-host at pag-route na may kamalayan sa cache upang bawasan ang gastos at mapabuti ang throughput—lalo na sa mga workload ng chat na may mataas na QPS na may mga ulit na prompt.
Mga dapat bantayan. Para sa malalim pamamahala ng enterprise (hal., mga export ng SIEM, patakaran sa buong organisasyon), maraming mga koponan ipares ang OpenRouter sa Portkey o Kong AI Gateway.
Portkey

Ano ito. Isang AI platform ng operasyon + gateway na may programmable mga fallback, rate-limit na mga playbook, at simple/semantic na cache, dagdag pa mga trace/metric para sa kontrol na estilo ng SRE.
- Mga nested fallback at conditional routing — ipahayag ang mga retry tree (hal., i-retry ang 429s; lumipat sa 5xx; magpalit kapag may mga spike sa latency).
- Semantic cache — madalas na nananalo sa maiikling prompt/mensahe (may mga limitasyon).
- Virtual na mga susi/badyet — panatilihin ang paggamit ng koponan/proyekto sa patakaran.
Magandang akma kapag. Kailangan mo pag-ruruta batay sa patakaran na may first-class na observability, at komportable kang magpatakbo ng isang tarangkahan layer sa harap ng isa o higit pang mga router/mga pamilihan.
Kong AI Gateway

Ano ito. Isang gateway ng gilid na nagdadala mga plugin ng AI, pamamahala, at analytics sa loob ng Kong ecosystem (sa pamamagitan ng Konnect o self-managed). Ito ay imprastraktura—isang malakas na tugma kapag ang iyong API platform ay umiikot na sa Kong at kailangan mo ng sentral na patakaran/audit.
Magandang akma kapag. Pamamahala sa Edge, auditability, pananatili ng data, at sentralisadong kontrol ay hindi maaaring pag-usapan sa iyong kapaligiran.
Mga dapat bantayan. Asahan pag-setup at pagpapanatili. Maraming mga koponan ipares ang Kong sa isang router ng pamilihan (hal., ShareAI/OpenRouter) para sa pagpili ng provider at kontrol sa gastos.
Pag-isahin

Ano ito. A router na batay sa datos na nag-o-optimize para sa gastos/bilis/kalidad gamit live na benchmarks. Inilalantad nito ang isang unibersal na API at ina-update ang mga pagpipilian ng modelo ayon sa rehiyon/workload.
Magandang akma kapag. Gusto mo pagpili na gabay ng benchmark na patuloy na ina-adjust batay sa aktwal na performance.
Orq.ai

Ano ito. Isang generative AI kolaborasyon + LLMOps platform: mga eksperimento, mga tagasuri (kasama ang RAG mga sukatan tulad ng kaugnayan/katiyakan/katatagan ng konteksto), mga deployment, at RBAC/VPC.
Magandang akma kapag. Kailangan mo eksperimento + pagsusuri na may pamamahala sa isang lugar—pagkatapos ay direktang i-deploy mula sa parehong interface.
LiteLLM

Ano ito. Isang open-source na proxy/gateway na may Tugma sa OpenAI mga endpoint, mga badyet at mga limitasyon sa rate, pag-log/mga sukatan, at isang Admin UI. I-deploy sa pamamagitan ng Docker/K8s/Helm; panatilihin ang trapiko sa iyong sariling network.
Magandang akma kapag. Gusto mo sariling pagho-host at buong kontrol sa imprastraktura na may direktang pagiging tugma para sa mga sikat na OpenAI-style SDKs.
Mga dapat bantayan. Tulad ng anumang OSS gateway, ikaw ang may-ari ng mga operasyon at mga pag-upgrade. Siguraduhing maglaan ng oras para sa pagmamanman, pag-scale, at mga update sa seguridad.
Mabilisang pagsisimula: tawagan ang isang modelo sa loob ng ilang minuto (ShareAI)
Magsimula sa Palaruan, pagkatapos kunin ang isang API key at ipadala. Sanggunian: Mabilis na pagsisimula ng API • Docs Tahanan • Mga Paglabas.
#!/usr/bin/env bash"
// ShareAI — Chat Completions (JavaScript, Node 18+);
Tip sa migrasyon: I-map ang iyong kasalukuyang mga modelo ng Requesty sa mga katumbas ng ShareAI, gayahin ang mga hugis ng request/response, at magsimula sa likod ng tampok na watawat. Magpadala ng 5–10% ng trapiko muna, ihambing ang latency/gastos/kalidad, pagkatapos ay mag-ramp. Kung nagpapatakbo ka rin ng gateway (Portkey/Kong), tiyakin na caching/pagbagsak ay hindi mag-double-trigger sa mga layer.
Paghahambing sa isang tingin
| Plataporma | Naka-host / Sariling-host | Pag-route at Mga Pagbagsak | Pagmamasid | Lawak (LLM + higit pa) | Pamamahala/Patakaran | Mga Tala |
|---|---|---|---|---|---|---|
| Requesty | Naka-host | Router na may failover; OpenAI-compatible | Built-in na monitoring/analytics | LLM-sentriko (chat/pagkumpleto) | Pamamahala sa antas ng organisasyon | Palitan ang base URL ng OpenAI sa Requesty; diin sa enterprise. |
| IbahagiAI | Hosted + network ng provider | Agarang failover; routing na ginagabayan ng marketplace | Mga log ng paggamit; mga istatistika ng marketplace | Malawak na katalogo ng modelo | Mga kontrol sa antas ng provider | Marketplace na Pinapagana ng Tao; magsimula sa Palaruan. |
| Eden AI | Naka-host | Lumipat ng mga provider; batch; caching | Pagsubaybay sa Gastos at API | LLM + imahe + OCR + pagsasalita + pagsasalin | Sentralisadong pagsingil/pamamahala ng susi | Paghahambing ng Modelo upang subukan ang mga provider nang magkatabi. |
| OpenRouter | Naka-host | Pag-route ng provider/modelo; pag-cache ng prompt | Impormasyon sa antas ng kahilingan | LLM-sentriko | Mga patakaran ng provider | Muling paggamit ng cache kung saan sinusuportahan; fallback kapag hindi magagamit. |
| Portkey | Hino-host & Gateway | Mga fallback ng patakaran; mga playbook ng rate-limit; semantikong cache | Mga trace/metric | LLM-una | Mga configuration ng gateway | Mahusay para sa mga guardrails na estilo ng SRE at patakaran ng org. |
| Kong AI Gateway | Sariling-host/Enterprise | Upstream routing gamit ang AI plugins | Metrics/audit gamit ang Kong | LLM-una | Malakas na pamamahala sa edge | Infra component; pares sa router/marketplace. |
| Pag-isahin | Naka-host | Routing na nakabatay sa datos ayon sa gastos/bilis/kalidad | Tagapagsiyasat ng benchmark | LLM-sentriko | Mga kagustuhan sa router | Modelong pagpili na ginagabayan ng benchmark. |
| Orq.ai | Naka-host | Mga retries/fallbacks sa orkestrasyon | Analytics ng platform; Mga tagasuri ng RAG | LLM + RAG + evals | Mga opsyon sa RBAC/VPC | Pokus sa kolaborasyon at eksperimento. |
| LiteLLM | Sariling-host/OSS | Subukang muli/pagbagsak; mga badyet/mga limitasyon | Pag-log/mga sukatan; Admin UI | LLM-sentriko | Buong kontrol sa infra | Tugma sa OpenAI; Docker/K8s/Helm deploy. |
Mga FAQs
Ano ang Requesty?
Isang LLM tarangkahan nag-aalok ng multi-provider routing sa pamamagitan ng isang OpenAI-compatible API na may monitoring, pamamahala, at kontrol sa gastos.
Ano ang pinakamahusay na mga alternatibo sa Requesty?
Nangungunang mga pagpipilian ay kinabibilangan ng IbahagiAI (transparency ng marketplace + instant failover), Eden AI (multimodal API + paghahambing ng modelo), OpenRouter (routing na may kamalayan sa cache), Portkey (gateway na may patakaran at semantic cache), Kong AI Gateway (pamamahala sa gilid), Pag-isahin (router na batay sa data), Orq.ai (LLMOps/mga tagasuri), at LiteLLM (self-hosted proxy).
Requesty vs ShareAI — alin ang mas maganda?
Pumili IbahagiAI kung gusto mo ng transparent na marketplace na nagpapakita presyo/latency/uptime/availability bago ka mag-route, kasama ang instant failover at builder-aligned economics. Pumili Requesty kung mas gusto mo ang isang single hosted gateway na may enterprise governance at komportable kang pumili ng mga provider nang walang marketplace view. Subukan ang ShareAI’s Pamilihan ng Modelo at Palaruan.
Requesty vs Eden AI — ano ang pagkakaiba?
Eden AI sumasaklaw LLMs + multimodal (vision/OCR, speech, translation) at kasama ang Paghahambing ng Modelo; Requesty ay mas LLM-sentriko na may routing/governance. Kung ang iyong roadmap ay nangangailangan ng OCR/speech/translation sa ilalim ng isang API, pinapasimple ng Eden AI ang delivery; para sa gateway-style routing, angkop ang Requesty.
Requesty vs OpenRouter — kailan pipiliin ang bawat isa?
Pumili OpenRouter kailan pag-cache ng prompt at muling paggamit ng warm-cache mahalaga (may tendensiya itong panatilihin ka sa parehong provider at bumabalik sa mga outage). Pumili Requesty para sa pamamahala ng enterprise gamit ang isang router at kung ang cache-aware provider stickiness ay hindi ang iyong pangunahing prayoridad.
Requesty vs Portkey vs Kong AI Gateway — router o gateway?
Requesty ay isang router. Portkey at Kong AI Gateway ay mga gateway: mahusay sila sa patakaran/mga guardrails (fallbacks, rate limits, analytics, edge governance). Maraming stack ang gumagamit ng pareho: isang gateway para sa org-wide policy + isang router/marketplace para sa pagpili ng modelo at kontrol sa gastos.
Requesty vs Unify — ano ang natatangi tungkol sa Unify?
Pag-isahin gumagamit live na benchmarks at mga dynamic na patakaran upang i-optimize para sa gastos/bilis/kalidad. Kung nais mo routing na nakabatay sa datos na nagbabago ayon sa rehiyon/workload, ang Unify ay kapani-paniwala; ang Requesty ay nakatuon sa gateway-style routing at pamamahala.
Requesty vs Orq.ai — alin para sa pagsusuri at RAG?
Orq.ai nagbibigay ng isang eksperimento/pagsusuri surface (kasama ang mga RAG evaluator), plus deployments at RBAC/VPC. Kung kailangan mo LLMOps + mga evaluator, maaaring magdagdag o palitan ng Orq.ai ang isang router sa mga unang yugto.
Requesty vs LiteLLM — naka-host vs self-hosted?
Requesty ay hosted. LiteLLM ay isang self-hosted proxy/gateway na may mga budget at rate-limit at isang Admin UI; mahusay kung nais mong panatilihin ang trapiko sa loob ng iyong VPC at kontrolin ang control plane.
Alin ang pinakamura para sa aking workload: Requesty, ShareAI, OpenRouter, LiteLLM?
Depende ito sa pagpili ng modelo, rehiyon, cacheability, at mga pattern ng trapiko. Mga router tulad ng ShareAI/OpenRouter maaaring magpababa ng gastos sa pamamagitan ng routing at cache-aware stickiness; mga gateway tulad ng Portkey ay nagdadagdag ng semantikong caching; LiteLLM nagpapababa ng overhead ng platform kung komportable kang patakbuhin ito. Benchmark gamit ang iyong mga prompt at subaybayan epektibong gastos bawat resulta—hindi lamang ang listahan ng presyo.
Paano ako lilipat mula Requesty patungo sa ShareAI na may minimal na pagbabago sa code?
I-map ang iyong mga modelo sa mga katumbas ng ShareAI, i-mirror ang mga hugis ng request/response, at magsimula sa likod ng isang tampok na watawat. I-route ang maliit na % muna, ihambing ang latency/gastos/kalidad, pagkatapos ay mag-ramp. Kung nagpapatakbo ka rin ng gateway, tiyakin na caching/pagbagsak huwag mag-double-trigger sa pagitan ng mga layer.
Saklaw ba ng artikulong ito ang “Requestly alternatives” din? (Requesty vs Requestly)
Oo—Requestly (kasama ang isang L) ay isang suite ng mga tool para sa developer/QA (HTTP interception, API mocking/pagsubok, mga patakaran, mga header) sa halip na isang LLM router. Kung naghahanap ka ng mga alternatibo sa Requestly, malamang na ikinukumpara mo ang Postman, Fiddler, mitmproxy, atbp. Kung ang ibig mong sabihin ay Requesty (LLM gateway), gamitin ang mga alternatibo sa gabay na ito. Kung nais mong makipag-usap nang live, mag-book ng pulong: meet.growably.ro/team/shareai.
Ano ang pinakamabilis na paraan upang subukan ang ShareAI nang walang buong integrasyon?
Maaari ba akong maging tagapagbigay ng ShareAI at kumita?
Oo. Sinuman ay maaaring mag-onboard bilang Komunidad or Kumpanya tagapagbigay gamit ang Windows/Ubuntu/macOS or Docker. Mag-ambag mga pagsabog sa idle-time o patakbuhin laging-naka-on. Piliin Mga Gantimpala (pera), Palitan (mga token/AI Prosumer), o Misyon (mag-donate ng % sa mga NGO). Tingnan ang Gabay sa Provider.
Mayroon bang isang “pinakamahusay” na alternatibo sa Requesty?
Walang nag-iisang panalo para sa bawat koponan. Kung pinahahalagahan mo ang transparency ng marketplace + instant failover + ekonomiya ng builder, magsimula sa IbahagiAI. Para sa multimodal mga workload (OCR/pagsasalita/pagsasalin), tingnan ang Eden AI. Kung kailangan mo pamamahala sa gilid, suriin Portkey or Kong AI Gateway. Mas gusto sariling pagho-host? Isaalang-alang LiteLLM.
Konklusyon
Habang Requesty ay isang malakas na gateway ng LLM, ang iyong pinakamahusay na pagpipilian ay nakasalalay sa mga priyoridad:
- Transparency ng Marketplace + katatagan: IbahagiAI
- Multimodal na saklaw sa ilalim ng isang API: Eden AI
- Routing na may kamalayan sa cache sa naka-host na anyo: OpenRouter
- Patakaran/mga guardrail sa gilid: Portkey or Kong AI Gateway
- Routing na nakabatay sa data: Pag-isahin
- LLMOps + mga tagasuri: Orq.ai
- Self-hosted na control plane: LiteLLM
Kung pumipili ng mga provider ayon sa presyo/latency/uptime/availability bago ang bawat ruta, agarang failover, at ekonomiyang nakahanay sa tagabuo ay nasa iyong checklist, buksan ang Palaruan, lumikha ng API key, at mag-browse sa Pamilihan ng Modelo upang i-route ang iyong susunod na kahilingan sa matalinong paraan.

