
EmbeddingGemma 而家喺 ShareAI 上面。
我哋宣佈 嵌入Gemma, ,Google 嘅緊湊型開放嵌入模型,而家可以喺 ShareAI 上面用到。.
喺 3 億參數, ,EmbeddingGemma 喺佢嘅規模上提供咗最先進嘅性能。佢係由 Gemma 3 配合 T5Gemma 初始化 並使用咗同 雙子座 模型背後相同嘅研究同技術。呢個模型會產生文本嘅向量表示,令佢非常適合用喺搜索同檢索任務,包括 分類, 聚類, ,同 語義相似度. 佢係用數據訓練嘅 100+ 種語言.
點解重要
模型嘅細細尺寸同裝置專注令佢喺資源有限嘅環境中實用—手機、筆記本電腦或者台式機—令最尖端嘅AI模型普及化,促進人人創新。.
基準
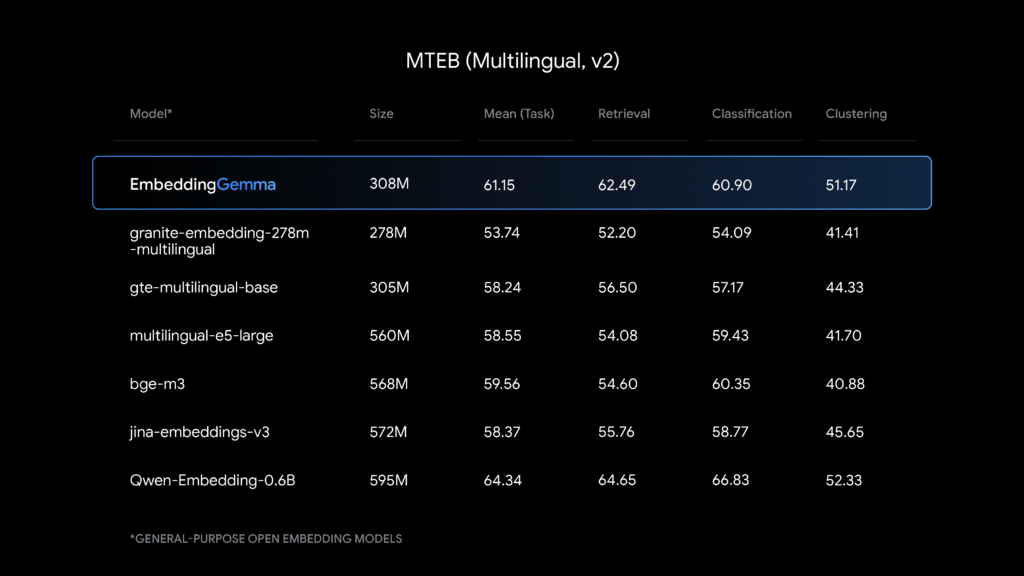
訓練數據集
EmbeddingGemma係用100+種語言嘅數據訓練嘅。.
- 網頁文件
多樣化嘅網頁文本集合確保接觸到廣泛嘅語言風格、主題同詞彙。數據集包括內容係 100+ 種語言. - 代碼同技術文件
包括編程語言同專業科學內容幫助模型學習結構同模式,改善對代碼同技術問題嘅理解。. - 合成同任務專用數據
精選嘅合成數據教導咗信息檢索、分類同情感分析嘅特定技能,微調咗常見嵌入應用嘅性能。.
呢個多元化來源嘅組合對於一個強大嘅多語言嵌入模型至關重要,可以處理廣泛嘅任務同數據格式。.
你可以建立嘅嘢
使用EmbeddingGemma嚟做 搜索同檢索, 語義相似度, 分類流程, ,同 聚類——特別係當你需要可以喺受限設備上運行嘅高質量嵌入時。.
參考
而家喺ShareAI上可用。.
運行佢。測試佢。發佈佢。.

