
ShareAI verpflichtet sich, Ihnen die neuesten und leistungsstärksten KI-Modelle zu bringen – und wir tun es heute wieder.
Vor wenigen Stunden, OpenAI veröffentlichte seine bahnbrechenden GPT-OSS Modelle, und Sie können sie bereits innerhalb des ShareAI-Netzwerks nutzen!
Die neu veröffentlichten Modelle—gpt-oss:20b und gpt-oss:120b—bieten außergewöhnliche lokale Chat-Erlebnisse, leistungsstarke Argumentationsfähigkeiten und erweiterten Support für fortgeschrittene Entwickler-Szenarien.
🚀 Starten Sie mit GPT-OSS auf ShareAI
Sie können diese Modelle jetzt mit der neuesten Version des ShareAI Windows-Clients ausprobieren.
- Laden Sie ShareAI für Windows herunter (Link zur Download-Seite)
Nach der Installation können Sie die GPT-OSS-Modelle direkt über die ShareAI-App herunterladen und ausführen – keine komplizierten Setups oder Konfigurationen erforderlich.
✨ GPT-OSS Funktions-Highlights
Hier ist der Grund, warum GPT-OSS ein Wendepunkt für Ihre KI-gesteuerten Workflows ist:
- Agentische Fähigkeiten:
Nutzen Sie integrierte Funktionen für Funktionsaufrufe, Web-Browsing, Python-Tool-Aufrufe und strukturierte Datenausgaben. - Volle Transparenz der Gedankenketten:
Erhalten Sie klare Einblicke in den Denkprozess des Modells, was einfacheres Debugging und größeres Vertrauen in generierte Ergebnisse ermöglicht. - Konfigurierbare Denkebenen:
Passen Sie den Denkaufwand (niedrig, mittel, hoch) einfach an Ihre Latenz- und Komplexitätsanforderungen an. - Feinabstimmungsfähige Architektur:
Passen Sie Modelle umfassend mit Parameter-Fine-Tuning für spezifische Anwendungsfälle an. - Erlaubnis Apache 2.0 Lizenz:
Innovieren Sie frei ohne restriktive Copyleft-Lizenzen oder Patentrisiken – perfekt für kommerzielle Einsätze und schnelle Experimente.
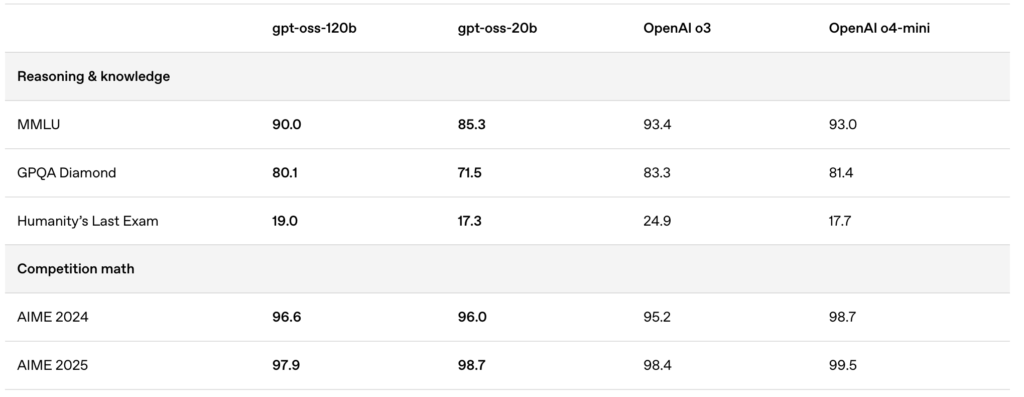
🔥 Optimiert mit MXFP4-Quantisierung
OpenAI hat die MXFP4-Quantisierung eingeführt, die den Speicherbedarf der GPT-OSS-Modelle erheblich reduziert:
- MXFP4-Format erklärt:
GPT-OSS-Modelle nutzen eine Quantisierungstechnik, bei der Mixture-of-Experts (MoE)-Gewichte auf nur 4,25 Bits pro Parameter quantisiert werden. Diese MoE-Gewichte machen über 90% der gesamten Modellparameter aus, was die Quantisierung unglaublich effizient macht. - Verbesserte Kompatibilität:
Diese optimierte Quantisierung ermöglicht:- Das gpt-oss:20b Modell läuft reibungslos auf Maschinen mit nur 16 GB Speicher.
- Das gpt-oss:120b Modell passt bequem auf eine einzelne 80GB-GPU.
ShareAI unterstützt dieses MXFP4-Format nativ – keine zusätzlichen Schritte, Konvertierungen oder Mühen erforderlich. Unser neuestes Engine-Update enthält neu entwickelte Kernel, die speziell für das MXFP4-Format entwickelt wurden, um maximale Leistung zu gewährleisten.
📌 GPT-OSS-Modelle jetzt verfügbar:
GPT-OSS:20B
- Ideal für latenzarme, spezialisierte Aufgaben oder lokale Bereitstellungen.
- Bietet robuste Leistung auch auf bescheidenen Hardware-Konfigurationen.
GPT-OSS:120B
- Liefert leistungsstarke Argumentation, fortschrittliche agentische Fähigkeiten und Vielseitigkeit, die für anspruchsvolle Aufgaben im großen Maßstab geeignet sind.
- Perfekt für Entwickler und Unternehmen, die tiefere Argumentation, höhere Genauigkeit und breitere KI-Anwendungen benötigen.
🛠️ Probieren Sie GPT-OSS noch heute aus
Bereit, die nächste Generation von KI-Fähigkeiten zu erleben?
- Laden Sie den ShareAI Windows-Client herunter (Link zur Download-Seite)
- Dokumentation anzeigen (Link zu Benutzerhandbüchern oder Tutorials)
Bleiben Sie dran—ShareAI erweitert weiterhin unsere Modellbibliothek und unterstützt Ihre KI-Projekte auf jedem Schritt des Weges.
Viel Spaß beim Prompten! 🚀

