
Artikel aktualisiert am: Juni 2026
Die besten LLM-Observability-Tools helfen Teams, eine einfache Produktionsfrage zu beantworten: Was ist tatsächlich in dieser KI-Anfrage passiert?
Diese Frage wird schnell schwierig. Eine einzelne Benutzeraktion kann einen Prompt, einen Abrufschritt, einen Modellaufruf, einen Fallback, einen Toolaufruf, einen Ausgabeparser, eine Bewertungsnote und ein Abrechnungsereignis auslösen. Wenn diese Schritte über Protokolle, Anbieter-Dashboards, benutzerdefinierte Tabellen und einmalige Traces verstreut sind, wird Debugging zu Archäologie.
Für KI-Apps, Agenten, Copiloten und RAG-Systeme sollte die LLM-Observability den gesamten Pfad zeigen: Prompts, Ausgaben, Latenz, Token-Nutzung, Kosten, Fehler, Wiederholungen, Modellrouten, Benutzermetadaten und das Verhalten nachgelagerter Tools.
Hier sind sieben Tools, die für Produktions-KI-Teams eine Bewertung wert sind, wobei SigNoz zuerst genannt wird, da es das Full-Stack-Observability-Problem löst, anstatt nur den LLM-Bereich zu zeigen.
Was man bei den besten LLM-Observability-Tools beachten sollte
LLM-Observability ist mehr als das Speichern von Prompts und Antworten. Eine nützliche Plattform sollte Ingenieur-, Produkt- und Betriebsteams helfen, Zuverlässigkeit, Kosten und Ausgabequalität gemeinsam zu verstehen.
- Spuren: Modellaufrufe, Abrufschritte, Toolaufrufe, Wiederholungen, Fallbacks und nachgelagerte Dienste.
- Metriken: Latenz, Durchsatz, Fehlerrate, Token-Nutzung, Modellnutzung, Routen-Gesundheit und Kosten.
- Protokolle: Anfrage-Metadaten, Anwendungsereignisse, Ausnahmen und Vorfallkontext.
- Bewertungen: Qualitätsbewertungen, Halluzinationsprüfungen, Relevanzprüfungen und Regressionstests.
- Filterung: Benutzer-, Arbeitsbereich-, Projekt-, Modell-, Routen-, Umgebungs- und Anwendungsmetadaten.
- OpenTelemetry-Unterstützung: ein sauberer Weg, um KI-Spuren mit dem Rest des Software-Stacks zu verbinden.
Das OpenTelemetry-Signale-Modell ist eine nützliche Grundlage, da moderne Produktions-Debugging von Spuren, Metriken, Logs und Kontext abhängt, die zusammenarbeiten.
1. SigNoz
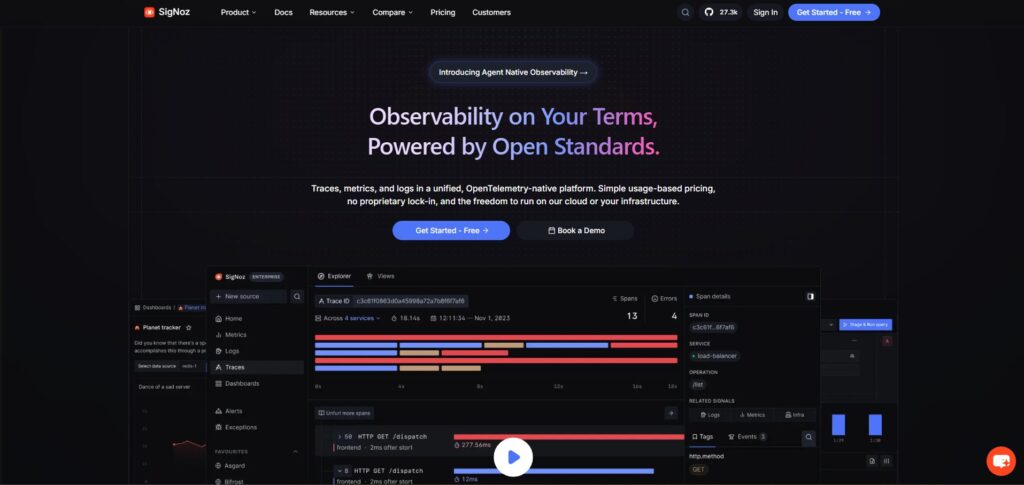
SigNoz ist das erste Tool, das wir für Teams bewerten würden, die LLM-Observability in einem umfassenderen Engineering-Observability-Stack wünschen. Es ist OpenTelemetry-nativ und bringt Spuren, Metriken, Logs, Ausnahmen, Dashboards und Warnungen in eine Plattform.
Bei ShareAI verwenden wir SigNoz als unsere zentrale All-in-One-Observability- und Tracing-Schicht. Das ist wichtig, weil KI-Probleme selten innerhalb eines Modellaufrufs bleiben. Eine schlechte Antwort kann API-Latenz, Anbieter-Routing, Wiederholungen, Datenbank-Timing, Warteschlangenverhalten, Abrechnungsereignisse und App-Ebene-Fehler umfassen. SigNoz gibt dem Team einen Ort, um diese Signale zu verbinden, anstatt zwischen getrennten Tools zu springen.
SigNoz ist besonders stark, wenn Sie möchten, dass LLM-Spuren neben normaler Anwendungs- und Infrastruktur-Telemetrie existieren. Für Teams, die bereits in OpenTelemetry, Servicekarten, Latenzspuren, Log-Korrelation und Warnungen denken, macht das SigNoz zu einer praktischen Grundlage für Produktions-KI-Systeme.
Am besten geeignet für: Teams, die LLM-Observability, App-Observability, Infrastruktur-Signale und Tracing an einem Ort wünschen.
2. Langfuse
Langfuse ist eine starke Open-Source-Option für LLM-Anwendungstracing. Es ist um Spuren, Sitzungen, Beobachtungen, Token-Nutzung, Latenz, Prompt-Management, Datensätze, Experimente und Bewertungen aufgebaut.
Langfuse ist eine gute Wahl, wenn der KI-Engineering-Workflow selbst das Gravitationszentrum ist. Wenn Ihr Team Prompt-Iteration, Spureninspektion, Kostenverfolgung und Bewertungs-Workflows in einer speziell entwickelten LLM-Oberfläche wünscht, ist Langfuse eine der klarsten Optionen.
Am besten geeignet für: Entwicklerteams, die Open-Source-LLM-Tracing, Prompt-Management und Bewertungs-Workflows wünschen.
3. LangSmith
LangSmith ist eine natürliche Wahl für Teams, die mit LangChain oder LangGraph arbeiten. Es konzentriert sich auf Tracing, Überwachung, Bewertung, Warnungen und Produktions-Debugging für LLM-Apps und -Agenten.
Der Hauptvorteil ist die Passung zum Ökosystem. Wenn Ihr Team LangChain bereits intensiv nutzt, kann LangSmith Traces, Bewertungsdurchläufe und Agenten-Debugging nahtlos in den Entwicklungsworkflow integrieren.
Am besten geeignet für: LangChain- und LangGraph-Teams, die eine enge Verbindung zwischen Observability und ihrem Agenten-Framework wünschen.
4. Helicone

Helicone ist nützlich für Teams, die eine leichte Observability-Schicht für OpenAI-kompatiblen API-Verkehr wünschen. Es ist oft attraktiv, wenn das erste Problem einfach ist: Anfragen, Latenz, Modellnutzung, Fehler, Benutzer und Kosten sehen, ohne eine benutzerdefinierte Analyseschicht zu erstellen.
Helicone ist nicht immer die tiefste Full-Stack-Observability-Plattform, aber es ist praktisch für Teams, die schnelle API-Ebene-Sichtbarkeit und Kostenüberwachung über LLM-Aufrufe hinweg benötigen.
Am besten geeignet für: Startups und Produktteams, die schnelle LLM-API-Observability und Nutzungsübersicht wünschen.
5. Arize Phoenix

Arize Phoenix ist eine Open-Source-Plattform für KI-Observability und -Bewertung. Sie unterstützt Tracing, Prompt-Engineering, Datensätze, Experimente und Bewertungs-Workflows mit Unterstützung für OpenTelemetry- und OpenInference-Instrumentierung.
Phoenix ist nützlich, wenn Debugging nicht ausreicht und Sie auch die Ausgabequalität mit Bewertungsdaten verbessern müssen. Teams können einzelne Durchläufe inspizieren, Ausgaben bewerten, Prompt-Änderungen vergleichen und Produktionsverhalten in Beweise für Iterationen umwandeln.
Am besten geeignet für: Teams, denen LLM-Bewertung, Experimente und Qualitätsverbesserung ebenso wichtig sind wie Trace-Inspektion.
6. PromptLayer
PromptLayer kombiniert Observability mit Prompt-Management. Es verfolgt Anfragen, Spans, Kosten, Latenz, Prompt-Versionen und Analysen, damit Teams sowohl das Produktionsverhalten als auch Änderungen an Prompts verstehen können.
PromptLayer ist eine gute Wahl, wenn Prompt-Operationen der Hauptworkflow sind. Wenn Ihr Team häufig fragt, welche Prompt-Version eine Regression verursacht hat, welche Anfrage fehlschlug oder wie ein Prompt über Modelle hinweg funktioniert, hält PromptLayer diese Historie nahe am Debugging-Prozess.
Am besten geeignet für: Teams, die Prompt-Versionierung, Prompt-Analysen und LLM-Anfrage-Überwachung zusammen wünschen.
Vergleich von LLM-Überwachungstools
| Werkzeug | Beste Passform | Hauptstärke |
|---|---|---|
| SigNoz | Vollständige KI- und App-Überwachung | OpenTelemetry-native Traces, Metriken, Logs, Dashboards und Warnungen |
| Langfuse | Open-Source-LLM-Engineering-Teams | LLM-Traces, Prompt-Management, Datensätze und Bewertungen |
| LangSmith | LangChain- und LangGraph-Teams | Framework-verbundene Tracing-, Monitoring- und Bewertungsfunktionen |
| Helicone | Schnelle API-Level-LLM-Sichtbarkeit | Anfragelogs, Nutzung, Latenz, Fehler und Kostenverfolgung |
| Arize Phoenix | Bewertungsintensive KI-Apps | Tracing, Experimente, Datensätze und Qualitätsbewertung |
| PromptLayer | Prompt-Operationen | Prompt-Versionen, Anforderungsnachverfolgungen, Latenz, Kosten und Analysen |
Wo ShareAI in einem Observability-Stack passt
ShareAI ist kein Ersatz für SigNoz, Langfuse, LangSmith oder andere Observability-Plattformen. Es ist ein KI-Marktplatz und eine API, die Kunden und Entwicklern hilft, über eine Integration auf 150+ Modelle zuzugreifen, Anfragen zu routen, intelligentes Failover zu nutzen und die KI-Nutzung über die Model-Zugriffsschicht zu verfolgen.
Für Entwickler ist ShareAI nützlich, wenn die Anwendung außerhalb von ShareAI erstellt wird, aber der KI-Verkehr geroutet, die Nutzung verfolgt, die Abrechnung und Zuschlagskontrolle durchgeführt und monatliche Entwicklerauszahlungen verwaltet werden müssen. Observability-Tools zeigen, was passiert ist. ShareAI hilft, wie KI-Inferenzverkehr geroutet und monetarisiert wird.
Die stärkste Konfiguration kombiniert beide Schichten. Verwenden Sie ShareAI für den Modellzugriff und die geroutete KI-Nutzung. Verwenden Sie SigNoz oder eine andere Observability-Plattform, um KI-Traces mit dem Rest Ihrer Anwendung, Infrastruktur und Incident-Response-Workflow zu verbinden.
Um die Model-Zugriffsschicht zu verbinden, beginnen Sie mit der ShareAI API-Referenz. Um Modelle vor dem Routing des Verkehrs zu vergleichen, durchsuchen Sie die ShareAI-Modellmarktplatz.
FAQ
Was sind die besten LLM-Observability-Tools?
Die besten LLM-Observability-Tools hängen vom Workflow ab. SigNoz ist stark für Full-Stack-Observability, Langfuse für Open-Source-LLM-Tracing, LangSmith für LangChain-Teams, Phoenix für eval-lastige Workflows und PromptLayer für Prompt-Operationen.
Warum steht SigNoz an erster Stelle auf dieser Liste?
SigNoz steht an erster Stelle, weil es LLM-Traces mit breiterer Anwendungstelemetrie verbindet. Bei ShareAI verwenden wir SigNoz als unsere zentrale Observability- und Tracing-Schicht, da KI-Vorfälle oft Modelle, APIs, Datenbanken, Warteschlangen, Logs, Metriken und Infrastruktur zusammen betreffen.
Was ist LLM-Observability?
LLM-Observability ist die Praxis des Nachverfolgens, Messens, Loggens und Bewertens des Verhaltens von KI-Anwendungen. Es umfasst normalerweise Prompts, Antworten, Tool-Aufrufe, Abrufschritte, Token-Nutzung, Kosten, Latenz, Fehler und Signale zur Ausgabequalität.
Wie unterscheidet sich LLM-Observability von normalem Logging?
Normales Logging zeichnet Ereignisse auf. LLM-Observability rekonstruiert den gesamten KI-Workflow, einschließlich Modelleingaben, -ausgaben, Zwischenschritten, Tool-Aufrufen, Kosten und Qualität. Es hilft Teams zu verstehen, warum eine KI-Antwort zustande kam, nicht nur, dass eine Anfrage erfolgt ist.
Brauche ich LLM-Observability, wenn ich bereits ein AI-Gateway nutze?
Ja. Ein AI-Gateway kann helfen, den Zugriff auf Modelle zu routen, zu messen und zu kontrollieren, während ein Observability-Tool hilft, das Verhalten der gesamten Anwendung zu debuggen und zu untersuchen. Die beiden Ebenen lösen unterschiedliche, aber komplementäre Probleme.
Ersetzt ShareAI ein Observability-Tool?
Nein. ShareAI ist ein KI-Marktplatz und eine API für Modellzugriff, Routing, Nutzung, Abrechnung und Monetarisierung für Builder. Es sollte mit Observability-Plattformen wie SigNoz kombiniert werden, wenn Teams vollständige Traces, Logs, Metriken, Dashboards und Warnungen benötigen.
Was sollten Teams in einer LLM-App nachverfolgen?
Teams sollten Benutzeranfragen, Prompt-Versionen, Modellaufrufe, Abrufschritte, Tool-Aufrufe, Wiederholungen, Fallbacks, Token-Nutzung, Latenz, Fehlerzustände und Qualitätsprüfungen der Ausgaben nachverfolgen. Für Agenten sind Tool-Auswahl und Ausführungsreihenfolge besonders wichtig.
Welches LLM-Observability-Tool ist am besten für Open-Source-Teams geeignet?
SigNoz, Langfuse, Arize Phoenix und WhyLabs LangKit haben alle starke Open-Source-Schwerpunkte. Die richtige Wahl hängt davon ab, ob das Team Full-Stack-Telemetrie, LLM-spezifisches Tracing, Evaluierungs-Workflows oder Monitoring der Ausgabequalität benötigt.
Welches LLM-Observability-Tool ist am besten für LangChain geeignet?
LangSmith ist die natürlichste Wahl für Teams, die bereits auf LangChain oder LangGraph standardisiert sind. Langfuse und Phoenix können ebenfalls gut funktionieren, abhängig vom bevorzugten Tracing-, Evaluierungs- und Hosting-Modell des Teams.
Wie hilft Observability bei der Kontrolle von KI-Kosten?
Observability verbindet Kosten mit Benutzern, Modellen, Prompts, Routen, Anwendungen und Workflows. Das hilft Teams, teure Prompts, endlose Schleifen, Routen mit hoher Latenz, wiederholte Wiederholungen und Funktionen zu finden, bei denen die Nutzung viel höher ist als erwartet.
Können Builder KI-Apps monetarisieren und trotzdem Observability nutzen?
Ja. Ein Builder kann KI-Inferenz-Traffic von einer App über ShareAI routen, eine Marge oder einen Zuschlag konfigurieren und trotzdem SigNoz oder ein anderes Observability-Tool verwenden, um die Anwendung, Traces, Logs, Fehler und Leistung zu überwachen.

