
Article mis à jour le : juin 2026
Les meilleurs outils d'observabilité LLM aident les équipes à répondre à une question simple en production : que s'est-il réellement passé dans cette requête IA ?
Cette question devient rapidement complexe. Une seule action utilisateur peut déclencher une invite, une étape de récupération, un appel de modèle, un mécanisme de secours, un appel d'outil, un analyseur de sortie, un score d'évaluation et un événement de facturation. Si ces étapes sont dispersées dans des journaux, des tableaux de bord de fournisseurs, des feuilles de calcul personnalisées et des traces ponctuelles, le débogage se transforme en archéologie.
Pour les applications IA, agents, copilotes et systèmes RAG, l'observabilité LLM devrait montrer tout le chemin : invites, sorties, latence, utilisation des jetons, coût, erreurs, nouvelles tentatives, itinéraires de modèles, métadonnées utilisateur et comportement des outils en aval.
Voici sept outils qui méritent d'être évalués par les équipes de production IA, avec SigNoz en premier car il résout le problème d'observabilité full-stack au lieu de montrer uniquement la partie LLM.
Ce qu'il faut rechercher dans les meilleurs outils d'observabilité LLM
L'observabilité LLM va au-delà du stockage des invites et des réponses. Une plateforme utile devrait aider les équipes d'ingénierie, de produit et d'opérations à comprendre ensemble la fiabilité, le coût et la qualité des sorties.
- Traces : appels de modèle, étapes de récupération, appels d'outil, nouvelles tentatives, mécanismes de secours et services en aval.
- Métriques : latence, débit, taux d'erreur, utilisation des jetons, utilisation du modèle, santé des itinéraires et coût.
- Journaux : métadonnées des requêtes, événements d'application, exceptions et contexte des incidents.
- Évaluations : scores de qualité, vérifications des hallucinations, vérifications de pertinence et tests de régression.
- Filtrage : utilisateur, espace de travail, projet, modèle, itinéraire, environnement et métadonnées d'application.
- Support OpenTelemetry : un chemin plus propre pour connecter les traces d'IA avec le reste de la pile logicielle.
Au modèle de signaux OpenTelemetry est une base utile car le débogage moderne en production dépend des traces, des métriques, des journaux et du contexte qui se déplacent ensemble.
1. SigNoz
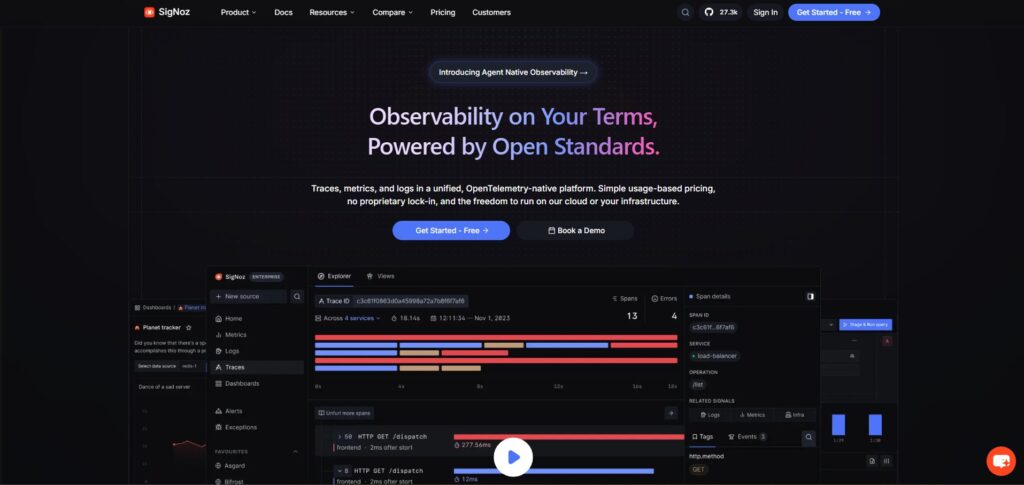
SigNoz est le premier outil que nous évaluerions pour les équipes qui souhaitent une observabilité LLM au sein d'une pile d'observabilité d'ingénierie plus large. Il est natif d'OpenTelemetry et regroupe les traces, les métriques, les journaux, les exceptions, les tableaux de bord et les alertes sur une seule plateforme.
Chez ShareAI, nous utilisons SigNoz comme notre couche centrale tout-en-un d'observabilité et de traçage. Cela est important car les problèmes d'IA ne restent rarement confinés à un seul appel de modèle. Une mauvaise réponse peut impliquer la latence de l'API, le routage du fournisseur, les tentatives de nouvelle connexion, le timing de la base de données, le comportement des files d'attente, les événements de facturation et les erreurs au niveau de l'application. SigNoz offre à l'équipe un endroit unique pour connecter ces signaux au lieu de passer d'un outil déconnecté à un autre.
SigNoz est particulièrement performant lorsque vous souhaitez que les traces LLM coexistent avec la télémétrie normale des applications et des infrastructures. Pour les équipes qui pensent déjà en termes d'OpenTelemetry, de cartes de services, de traces de latence, de corrélation des journaux et d'alertes, cela fait de SigNoz une base pratique pour les systèmes d'IA en production.
Idéal pour : équipes qui souhaitent une observabilité LLM, une observabilité des applications, des signaux d'infrastructure et un traçage en un seul endroit.
2. Langfuse
Langfuse est une option open-source solide pour le traçage des applications LLM. Il est construit autour des traces, des sessions, des observations, de l'utilisation des tokens, de la latence, de la gestion des prompts, des ensembles de données, des expériences et des évaluations.
Langfuse est adapté lorsque le flux de travail d'ingénierie de l'IA lui-même est le centre de gravité. Si votre équipe souhaite une itération des prompts, une inspection des traces, un suivi des coûts et des flux de travail d'évaluation dans une interface LLM spécialement conçue, Langfuse est l'une des options les plus claires.
Idéal pour : équipes de développeurs qui souhaitent un traçage LLM open-source, une gestion des prompts et des flux de travail d'évaluation.
3. LangSmith
LangSmith est un choix naturel pour les équipes travaillant avec LangChain ou LangGraph. Il se concentre sur le traçage, la surveillance, l'évaluation, les alertes et le débogage en production pour les applications et agents LLM.
L'avantage principal est l'adéquation avec l'écosystème. Si votre équipe utilise déjà largement LangChain, LangSmith peut rendre les traces, les évaluations et le débogage des agents proches du flux de développement.
Idéal pour : Équipes LangChain et LangGraph qui souhaitent une observabilité étroitement liée à leur cadre d'agents.
4. Hélicone

Helicone est utile pour les équipes qui souhaitent une couche d'observabilité légère autour du trafic API compatible OpenAI. Il est souvent attrayant lorsque le premier problème est simple : voir les requêtes, la latence, l'utilisation des modèles, les erreurs, les utilisateurs et les coûts sans construire une couche analytique personnalisée.
Helicone n'est pas toujours la plateforme d'observabilité full-stack la plus approfondie, mais elle est pratique pour les équipes qui ont besoin d'une visibilité rapide au niveau API et d'une surveillance des coûts sur les appels LLM.
Idéal pour : startups et équipes produit qui souhaitent une observabilité rapide des API LLM et une visibilité de l'utilisation.
5. Arize Phoenix

Arize Phoenix est une plateforme open-source d'observabilité et d'évaluation de l'IA. Elle prend en charge le traçage, l'ingénierie des prompts, les ensembles de données, les expériences et les flux de travail d'évaluation, avec prise en charge de l'instrumentation OpenTelemetry et OpenInference.
Phoenix est utile lorsque le débogage ne suffit pas et que vous devez également améliorer la qualité des résultats avec des données d'évaluation. Les équipes peuvent inspecter des exécutions individuelles, noter les résultats, comparer les modifications des prompts et transformer le comportement en production en preuves pour l'itération.
Idéal pour : équipes qui se soucient autant de l'évaluation des LLM, des expériences et de l'amélioration de la qualité que de l'inspection des traces.
6. PromptLayer
PromptLayer combine l'observabilité avec la gestion des prompts. Il suit les requêtes, les spans, les coûts, la latence, les versions des prompts et les analyses afin que les équipes puissent comprendre à la fois le comportement en production et les modifications des prompts.
PromptLayer est un bon choix lorsque les opérations de prompt sont le principal flux de travail. Si votre équipe demande souvent quelle version de prompt a causé une régression, quelle requête a échoué ou comment un prompt fonctionne sur différents modèles, PromptLayer conserve cet historique près du processus de débogage.
Idéal pour : équipes qui souhaitent le versionnage des prompts, des analyses de prompts et l'observabilité des requêtes LLM ensemble.
Outils d'observabilité LLM comparés
| Outil | Meilleur ajustement | Force principale |
|---|---|---|
| SigNoz | Observabilité complète de l'IA et des applications | Traces, métriques, journaux, tableaux de bord et alertes natifs OpenTelemetry |
| Langfuse | Équipes d'ingénierie LLM open-source | Traces LLM, gestion des prompts, ensembles de données et évaluations |
| LangSmith | Équipes LangChain et LangGraph | Traces, surveillance et évaluation connectées au framework |
| Helicone | Visibilité rapide au niveau API pour LLM | Journaux de requêtes, utilisation, latence, erreurs et suivi des coûts |
| Arize Phoenix | Applications IA axées sur l'évaluation | Traces, expériences, ensembles de données et évaluation de la qualité |
| PromptLayer | Opérations de prompt | Versions de prompts, traces de requêtes, latence, coût et analyses |
Où ShareAI s'intègre dans une pile d'observabilité
ShareAI n'est pas un remplacement pour SigNoz, Langfuse, LangSmith ou toute autre plateforme d'observabilité. C'est un marché et une API d'IA qui aide les clients et les développeurs à accéder à plus de 150 modèles via une seule intégration, à router les requêtes, à utiliser un basculement intelligent et à suivre l'utilisation de l'IA via la couche d'accès aux modèles.
Pour les développeurs, ShareAI est utile lorsque l'application est construite en dehors de ShareAI mais que son trafic IA nécessite un routage, un suivi d'utilisation, une facturation, un contrôle des surtaxes et des paiements mensuels pour les développeurs. Les outils d'observabilité montrent ce qui s'est passé. ShareAI aide à contrôler comment le trafic d'inférence IA est routé et monétisé.
La configuration la plus solide combine les deux couches. Utilisez ShareAI pour l'accès aux modèles et l'utilisation routée de l'IA. Utilisez SigNoz ou une autre plateforme d'observabilité pour connecter les traces IA avec le reste de votre application, infrastructure et flux de travail de réponse aux incidents.
Pour connecter la couche d'accès aux modèles, commencez par le Référentiel API ShareAI. Pour comparer les modèles avant de router le trafic, parcourez le marché des modèles ShareAI.
FAQ
Quels sont les meilleurs outils d'observabilité LLM ?
Les meilleurs outils d'observabilité LLM dépendent du flux de travail. SigNoz est solide pour l'observabilité full-stack, Langfuse pour le traçage LLM open-source, LangSmith pour les équipes LangChain, Phoenix pour les flux de travail axés sur l'évaluation, et PromptLayer pour les opérations de prompts.
Pourquoi SigNoz est-il en premier sur cette liste ?
SigNoz est en premier car il connecte les traces LLM avec une télémétrie d'application plus large. Chez ShareAI, nous utilisons SigNoz comme notre couche centrale d'observabilité et de traçage car les incidents IA impliquent souvent des modèles, des API, des bases de données, des files d'attente, des journaux, des métriques et l'infrastructure ensemble.
Qu'est-ce que l'observabilité LLM ?
L'observabilité LLM est la pratique de traçage, mesure, journalisation et évaluation du comportement des applications IA. Elle inclut généralement les prompts, réponses, appels d'outils, étapes de récupération, utilisation des tokens, coût, latence, erreurs et signaux de qualité des sorties.
En quoi l'observabilité LLM est-elle différente de la journalisation normale ?
Les journaux normaux enregistrent les événements. L'observabilité des LLM reconstruit le flux de travail complet de l'IA, y compris les entrées, les sorties, les étapes intermédiaires, les appels d'outils, les coûts et la qualité. Cela aide les équipes à comprendre pourquoi une réponse de l'IA s'est produite, et pas seulement qu'une requête a eu lieu.
Ai-je besoin de l'observabilité des LLM si j'utilise déjà une passerelle IA ?
Oui. Une passerelle IA peut aider à acheminer, mesurer et contrôler l'accès au modèle, tandis qu'un outil d'observabilité aide à déboguer et à enquêter sur le comportement dans l'ensemble de l'application. Les deux couches résolvent des problèmes différents mais complémentaires.
ShareAI remplace-t-il un outil d'observabilité ?
Non. ShareAI est un marché d'IA et une API pour l'accès aux modèles, l'acheminement, l'utilisation, la facturation et la monétisation des Builders. Il doit être associé à des plateformes d'observabilité comme SigNoz lorsque les équipes ont besoin de traces complètes, de journaux, de métriques, de tableaux de bord et d'alertes.
Que doivent tracer les équipes dans une application LLM ?
Les équipes doivent tracer les requêtes des utilisateurs, les versions des invites, les appels de modèles, les étapes de récupération, les appels d'outils, les nouvelles tentatives, les solutions de secours, l'utilisation des jetons, la latence, les états d'erreur et les contrôles de qualité des sorties. Pour les agents, la sélection des outils et l'ordre d'exécution sont particulièrement importants.
Quel outil d'observabilité LLM est le meilleur pour les équipes open-source ?
SigNoz, Langfuse, Arize Phoenix et WhyLabs LangKit ont tous de solides angles open-source. Le choix approprié dépend de si l'équipe a besoin de télémétrie complète, de traçage spécifique aux LLM, de flux de travail d'évaluation ou de surveillance de la qualité des sorties.
Quel outil d'observabilité LLM est le meilleur pour LangChain ?
LangSmith est le choix le plus naturel pour les équipes déjà standardisées sur LangChain ou LangGraph. Langfuse et Phoenix peuvent également bien fonctionner selon le modèle de traçage, d'évaluation et d'hébergement préféré de l'équipe.
Comment l'observabilité aide-t-elle à contrôler les coûts de l'IA ?
L'observabilité relie les coûts aux utilisateurs, aux modèles, aux invites, aux routes, aux applications et aux flux de travail. Cela aide les équipes à identifier les invites coûteuses, les boucles incontrôlées, les routes à haute latence, les nouvelles tentatives répétées et les fonctionnalités où l'utilisation est beaucoup plus élevée que prévu.
Les Builders peuvent-ils monétiser les applications IA tout en utilisant l'observabilité ?
Oui. Un Builder peut acheminer le trafic d'inférence IA d'une application via ShareAI, configurer une marge ou une surcharge, et continuer à utiliser SigNoz ou un autre outil d'observabilité pour surveiller l'application, les traces, les journaux, les erreurs et les performances.

