
Artikulo na-update noong: Hunyo 2026
Ang pinakamahusay na mga tool sa LLM observability ay tumutulong sa mga koponan na sagutin ang isang simpleng tanong sa produksyon: ano ang talagang nangyari sa loob ng kahilingang AI na ito?
Ang tanong na iyon ay nagiging mahirap agad. Ang isang aksyon ng user ay maaaring mag-trigger ng prompt, retrieval step, model call, fallback, tool call, output parser, evaluation score, at billing event. Kung ang mga hakbang na iyon ay nakakalat sa mga log, provider dashboards, custom spreadsheets, at one-off traces, ang debugging ay nagiging arkeolohiya.
Para sa mga AI apps, agents, copilots, at mga sistema ng RAG, ang LLM observability ay dapat ipakita ang buong landas: prompts, outputs, latency, token usage, cost, errors, retries, model routes, user metadata, at downstream tool behavior.
Narito ang pitong tool na sulit suriin para sa mga produksyon ng AI teams, na may SigNoz sa unahan dahil nilulutas nito ang problema sa full-stack observability sa halip na ipakita lamang ang LLM slice.
Ano ang Dapat Hanapin sa Pinakamahusay na Mga Tool sa LLM Observability
Ang LLM observability ay higit pa sa pag-iimbak ng mga prompt at tugon. Ang isang kapaki-pakinabang na platform ay dapat tumulong sa engineering, product, at operations teams na maunawaan ang pagiging maaasahan, gastos, at kalidad ng output nang magkasama.
- Mga Traces: model calls, retrieval steps, tool calls, retries, fallbacks, at downstream services.
- Mga Sukatan: latency, throughput, error rate, token usage, model usage, route health, at cost.
- Mga Log: request metadata, application events, exceptions, at incident context.
- Mga Pagsusuri: quality scores, hallucination checks, relevance checks, at regression tests.
- Pag-filter: user, workspace, project, model, route, environment, at application metadata.
- Suporta sa OpenTelemetry: isang mas malinis na landas upang ikonekta ang mga bakas ng AI sa natitirang bahagi ng software stack.
Sa Modelo ng mga signal ng OpenTelemetry ay isang kapaki-pakinabang na baseline dahil ang modernong debugging ng produksyon ay nakasalalay sa mga bakas, sukatan, log, at konteksto na gumagalaw nang magkasama.
1. SigNoz
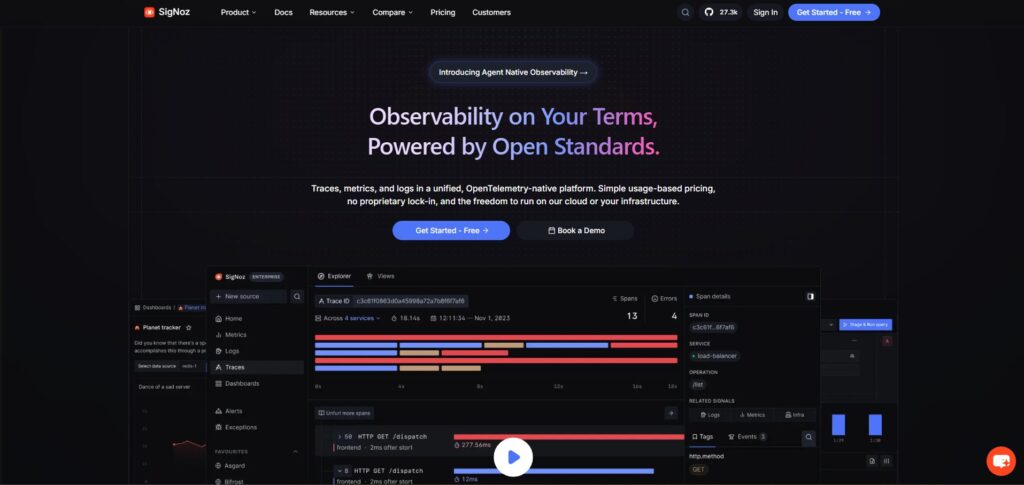
SigNoz ay ang unang tool na aming susuriin para sa mga team na nais ang LLM observability sa loob ng mas malawak na engineering observability stack. Ito ay OpenTelemetry-native at nagdadala ng mga bakas, sukatan, log, eksepsyon, dashboard, at alerto sa isang platform.
Sa ShareAI, ginagamit namin ang SigNoz bilang aming sentral na all-in-one observability at tracing layer. Mahalaga iyon dahil ang mga isyu sa AI ay bihirang manatili sa isang tawag ng modelo. Ang isang masamang tugon ay maaaring may kinalaman sa latency ng API, routing ng provider, retries, timing ng database, pag-uugali ng queue, mga kaganapan sa pagsingil, at mga error sa antas ng app. Binibigyan ng SigNoz ang team ng isang lugar upang ikonekta ang mga signal na iyon sa halip na tumalon sa pagitan ng mga disconnected na tool.
Ang SigNoz ay partikular na malakas kapag nais mong ang mga bakas ng LLM ay mabuhay sa tabi ng normal na telemetry ng aplikasyon at imprastraktura. Para sa mga team na iniisip na sa OpenTelemetry, mga mapa ng serbisyo, mga bakas ng latency, correlation ng log, at alerto, ginagawa nitong SigNoz ang isang praktikal na pundasyon para sa mga sistema ng produksyon ng AI.
Pinakamainam para sa: mga team na nais ang LLM observability, app observability, mga signal ng imprastraktura, at tracing sa isang lugar.
2. Langfuse
Langfuse ay isang malakas na open-source na opsyon para sa LLM application tracing. Ito ay binuo sa paligid ng mga bakas, sesyon, obserbasyon, paggamit ng token, latency, pamamahala ng prompt, datasets, eksperimento, at mga pagsusuri.
Ang Langfuse ay angkop kapag ang workflow ng AI engineering mismo ang sentro ng grabidad. Kung ang iyong team ay nais ang prompt iteration, inspeksyon ng bakas, pagsubaybay sa gastos, at eval workflows sa isang purpose-built na LLM interface, ang Langfuse ay isa sa mga pinakamalinaw na opsyon.
Pinakamainam para sa: mga team ng developer na nais ang open-source na LLM tracing, pamamahala ng prompt, at mga workflow ng pagsusuri.
3. LangSmith
LangSmith ay isang natural na pagpipilian para sa mga team na gumagamit ng LangChain o LangGraph. Nakatuon ito sa tracing, monitoring, evaluation, alerts, at production debugging para sa mga LLM app at agent.
Ang pangunahing bentahe ay ang akmang ecosystem. Kung ang iyong team ay malawak nang gumagamit ng LangChain, maaaring gawing mas malapit ng LangSmith ang mga trace, evaluation run, at agent debugging sa workflow ng development.
Pinakamainam para sa: Mga team ng LangChain at LangGraph na nais ng observability na mahigpit na konektado sa kanilang agent framework.
4. Helicone

Ang Helicone ay kapaki-pakinabang para sa mga team na nais ng magaan na observability layer sa paligid ng OpenAI-compatible na API traffic. Madalas itong kaakit-akit kapag ang unang problema ay simple: makita ang mga request, latency, paggamit ng modelo, error, mga user, at gastos nang hindi gumagawa ng custom analytics layer.
Ang Helicone ay hindi palaging ang pinakamalalim na full-stack observability platform, ngunit praktikal ito para sa mga team na nangangailangan ng mabilis na visibility sa API-level at monitoring ng gastos sa mga LLM call.
Pinakamainam para sa: mga startup at product team na nais ng mabilis na LLM API observability at visibility ng paggamit.
5. Arize Phoenix

Arize Phoenix ay isang open-source na AI observability at evaluation platform. Sinusuportahan nito ang tracing, prompt engineering, datasets, experiments, at evaluation workflows, na may suporta para sa OpenTelemetry at OpenInference instrumentation.
Ang Phoenix ay kapaki-pakinabang kapag ang debugging ay hindi sapat at kailangan mo ring pagbutihin ang kalidad ng output gamit ang evaluation data. Maaaring inspeksyunin ng mga team ang mga indibidwal na run, i-score ang mga output, ihambing ang mga pagbabago sa prompt, at gawing ebidensya para sa iteration ang production behavior.
Pinakamainam para sa: mga team na nagbibigay-halaga sa LLM evaluation, eksperimento, at pagpapabuti ng kalidad tulad ng sa trace inspection.
6. PromptLayer
PromptLayer pinagsasama ang observability sa prompt management. Sinusubaybayan nito ang mga request, span, gastos, latency, mga bersyon ng prompt, at analytics upang maunawaan ng mga team ang parehong production behavior at mga pagbabago sa prompt.
Ang PromptLayer ay angkop kapag ang mga operasyon ng prompt ang pangunahing workflow. Kung madalas itanong ng iyong team kung aling bersyon ng prompt ang nagdulot ng regression, kung aling request ang nasira, o kung paano gumaganap ang isang prompt sa iba't ibang modelo, pinapanatili ng PromptLayer ang kasaysayang iyon malapit sa debugging loop.
Pinakamainam para sa: mga team na nais ng prompt versioning, prompt analytics, at LLM request observability nang magkasama.
Mga Kasangkapan sa LLM Observability na Ihinahambing
| Kasangkapan | Pinakamainam na akma | Pangunahing lakas |
|---|---|---|
| SigNoz | Full-stack AI at app observability | OpenTelemetry-native traces, metrics, logs, dashboards, at alerts |
| Langfuse | Mga open-source na LLM engineering team | LLM traces, pamamahala ng prompt, datasets, at evals |
| LangSmith | Mga team ng LangChain at LangGraph | Framework-connected tracing, monitoring, at evaluation |
| Helicone | Mabilis na visibility ng LLM sa antas ng API | Mga log ng request, paggamit, latency, errors, at pagsubaybay sa gastos |
| Arize Phoenix | Mga AI app na mabigat sa evaluation | Tracing, eksperimento, datasets, at pagsusuri ng kalidad |
| PromptLayer | Mga operasyon ng prompt | Mga bersyon ng prompt, mga trace ng kahilingan, latency, gastos, at analytics |
Kung Saan Nababagay ang ShareAI Sa Isang Observability Stack
Ang ShareAI ay hindi kapalit ng SigNoz, Langfuse, LangSmith, o anumang iba pang platform ng observability. Ito ay isang AI marketplace at API na tumutulong sa mga customer at Builders na ma-access ang 150+ na modelo sa pamamagitan ng isang integrasyon, mag-route ng mga kahilingan, gumamit ng smart failover, at subaybayan ang paggamit ng AI sa pamamagitan ng model-access layer.
Para sa mga Builders, ang ShareAI ay kapaki-pakinabang kapag ang aplikasyon ay itinayo sa labas ng ShareAI ngunit ang AI traffic nito ay nangangailangan ng routing, usage tracking, billing, surcharge control, at buwanang payout para sa Builders. Ang mga observability tools ay nagpapakita kung ano ang nangyari. Ang ShareAI ay tumutulong sa pagkontrol kung paano niruruta at pinopondohan ang AI inference traffic.
Ang pinakamalakas na setup ay pinagsasama ang parehong layer. Gamitin ang ShareAI para sa model access at routed AI usage. Gamitin ang SigNoz o ibang observability platform upang ikonekta ang AI traces sa iba pang bahagi ng iyong aplikasyon, imprastraktura, at workflow ng incident response.
Upang ikonekta ang model-access layer, magsimula sa Sanggunian ng API ng ShareAI. Upang ikumpara ang mga modelo bago i-route ang traffic, mag-browse sa Pamilihan ng modelo ng ShareAI.
FAQ
Ano ang pinakamahusay na mga tool para sa LLM observability?
Ang pinakamahusay na mga tool para sa LLM observability ay nakadepende sa workflow. Malakas ang SigNoz para sa full-stack observability, Langfuse para sa open-source LLM tracing, LangSmith para sa mga LangChain teams, Phoenix para sa eval-heavy workflows, at PromptLayer para sa prompt operations.
Bakit ang SigNoz ang una sa listahang ito?
Ang SigNoz ang una dahil ikinokonekta nito ang LLM traces sa mas malawak na application telemetry. Sa ShareAI, ginagamit namin ang SigNoz bilang aming central observability at tracing layer dahil ang mga AI incidents ay madalas na may kasamang mga modelo, API, database, queues, logs, metrics, at imprastraktura nang sabay-sabay.
Ano ang LLM observability?
Ang LLM observability ay ang pagsasanay ng pag-trace, pagsukat, pag-log, at pagsusuri ng AI application behavior. Karaniwan itong kasama ang mga prompt, responses, tool calls, retrieval steps, token usage, gastos, latency, errors, at mga signal ng kalidad ng output.
Paano naiiba ang LLM observability sa normal na pag-log?
Ang normal na pag-log ay nagtatala ng mga kaganapan. Ang LLM observability ay muling binubuo ang buong AI workflow, kabilang ang mga input ng modelo, output, mga intermediate na hakbang, mga tawag sa tool, gastos, at kalidad. Tinutulungan nito ang mga team na maunawaan kung bakit nangyari ang isang AI na tugon, hindi lamang na naganap ang isang kahilingan.
Kailangan ko ba ng LLM observability kung gumagamit na ako ng AI gateway?
Oo. Ang isang AI gateway ay makakatulong sa pag-route, pag-meter, at pagkontrol sa pag-access ng modelo, habang ang isang observability tool ay tumutulong sa pag-debug at pagsisiyasat ng pag-uugali sa buong aplikasyon. Ang dalawang layer ay naglutas ng magkaibang ngunit magkakaugnay na mga problema.
Pinalitan ba ng ShareAI ang isang observability tool?
Hindi. Ang ShareAI ay isang AI marketplace at API para sa pag-access ng modelo, pag-route, paggamit, pagsingil, at monetization ng Builder. Dapat itong ipares sa mga observability platform tulad ng SigNoz kapag kailangan ng mga team ng buong traces, logs, metrics, dashboards, at alerts.
Ano ang dapat i-trace ng mga team sa isang LLM app?
Dapat i-trace ng mga team ang mga kahilingan ng user, mga bersyon ng prompt, mga tawag sa modelo, mga hakbang sa retrieval, mga tawag sa tool, retries, fallbacks, paggamit ng token, latency, mga estado ng error, at mga pagsusuri sa kalidad ng output. Para sa mga ahente, ang pagpili ng tool at pagkakasunod-sunod ng pagpapatupad ay lalong mahalaga.
Aling LLM observability tool ang pinakamahusay para sa mga open-source na team?
Ang SigNoz, Langfuse, Arize Phoenix, at WhyLabs LangKit ay lahat may malalakas na open-source na aspeto. Ang tamang pagpili ay nakadepende kung kailangan ng team ng full-stack telemetry, LLM-specific tracing, evaluation workflows, o output quality monitoring.
Aling LLM observability tool ang pinakamahusay para sa LangChain?
Ang LangSmith ang pinaka-natural na akma para sa mga team na naka-standardize na sa LangChain o LangGraph. Ang Langfuse at Phoenix ay maaari ring gumana nang maayos depende sa ginustong tracing, evaluation, at hosting model ng team.
Paano nakakatulong ang observability sa pagkontrol ng gastos sa AI?
Ang observability ay nag-uugnay ng gastos sa mga user, modelo, prompt, ruta, aplikasyon, at workflow. Tinutulungan nito ang mga team na mahanap ang mga mahal na prompt, runaway loops, high-latency routes, paulit-ulit na retries, at mga feature kung saan ang paggamit ay mas mataas kaysa inaasahan.
Maaari bang mag-monetize ang mga Builder ng AI apps at gumamit pa rin ng observability?
Oo. Ang isang Builder ay maaaring mag-route ng AI inference traffic mula sa isang app sa pamamagitan ng ShareAI, mag-configure ng margin o surcharge, at gumamit pa rin ng SigNoz o ibang observability tool upang subaybayan ang aplikasyon, traces, logs, errors, at performance.

