
บทความอัปเดตเมื่อ: มิถุนายน 2026
เครื่องมือสังเกตการณ์ LLM ที่ดีที่สุดช่วยทีมตอบคำถามง่าย ๆ เกี่ยวกับการผลิต: เกิดอะไรขึ้นจริง ๆ ภายในคำขอ AI นี้?
คำถามนั้นกลายเป็นเรื่องยากอย่างรวดเร็ว การกระทำของผู้ใช้เพียงครั้งเดียวสามารถกระตุ้นคำสั่ง, ขั้นตอนการดึงข้อมูล, การเรียกโมเดล, การสำรองข้อมูล, การเรียกเครื่องมือ, ตัวแยกผลลัพธ์, คะแนนการประเมิน, และเหตุการณ์การเรียกเก็บเงิน หากขั้นตอนเหล่านั้นกระจัดกระจายอยู่ในบันทึก, แดชบอร์ดของผู้ให้บริการ, สเปรดชีตที่กำหนดเอง, และการติดตามแบบเฉพาะ การแก้ไขข้อบกพร่องจะกลายเป็นการขุดค้นทางโบราณคดี.
สำหรับแอป AI, ตัวแทน, ผู้ช่วย, และระบบ RAG, การสังเกตการณ์ LLM ควรแสดงเส้นทางทั้งหมด: คำสั่ง, ผลลัพธ์, ความล่าช้า, การใช้โทเค็น, ค่าใช้จ่าย, ข้อผิดพลาด, การลองใหม่, เส้นทางโมเดล, ข้อมูลเมตาของผู้ใช้, และพฤติกรรมเครื่องมือปลายน้ำ.
นี่คือเครื่องมือเจ็ดอย่างที่ควรค่าแก่การประเมินสำหรับทีมผลิต AI โดยมี SigNoz เป็นอันดับแรกเพราะมันแก้ปัญหาการสังเกตการณ์แบบเต็มสแต็กแทนที่จะแสดงเฉพาะส่วนของ LLM.
สิ่งที่ควรมองหาในเครื่องมือสังเกตการณ์ LLM ที่ดีที่สุด
การสังเกตการณ์ LLM เป็นมากกว่าการจัดเก็บคำสั่งและการตอบกลับ แพลตฟอร์มที่มีประโยชน์ควรช่วยทีมวิศวกรรม, ผลิตภัณฑ์, และการดำเนินงานเข้าใจความน่าเชื่อถือ, ค่าใช้จ่าย, และคุณภาพของผลลัพธ์ร่วมกัน.
- ร่องรอย: การเรียกโมเดล, ขั้นตอนการดึงข้อมูล, การเรียกเครื่องมือ, การลองใหม่, การสำรองข้อมูล, และบริการปลายน้ำ.
- เมตริก: ความล่าช้า, อัตราการส่งผ่าน, อัตราข้อผิดพลาด, การใช้โทเค็น, การใช้โมเดล, สุขภาพเส้นทาง, และค่าใช้จ่าย.
- บันทึก: ข้อมูลเมตาของคำขอ, เหตุการณ์แอปพลิเคชัน, ข้อยกเว้น, และบริบทของเหตุการณ์.
- การประเมินผล: คะแนนคุณภาพ, การตรวจสอบภาพหลอน, การตรวจสอบความเกี่ยวข้อง, และการทดสอบการถดถอย.
- การกรอง: ผู้ใช้, พื้นที่ทำงาน, โครงการ, โมเดล, เส้นทาง, สภาพแวดล้อม, และข้อมูลเมตาของแอปพลิเคชัน.
- การสนับสนุน OpenTelemetry: เส้นทางที่สะอาดขึ้นเพื่อเชื่อมโยงร่องรอย AI กับส่วนที่เหลือของซอฟต์แวร์สแต็ก.
โมเดล โมเดลสัญญาณ OpenTelemetry เป็นพื้นฐานที่มีประโยชน์เพราะการดีบักในระบบผลิตสมัยใหม่ขึ้นอยู่กับร่องรอย, เมตริก, ล็อก และบริบทที่เคลื่อนที่ไปด้วยกัน.
1. SigNoz
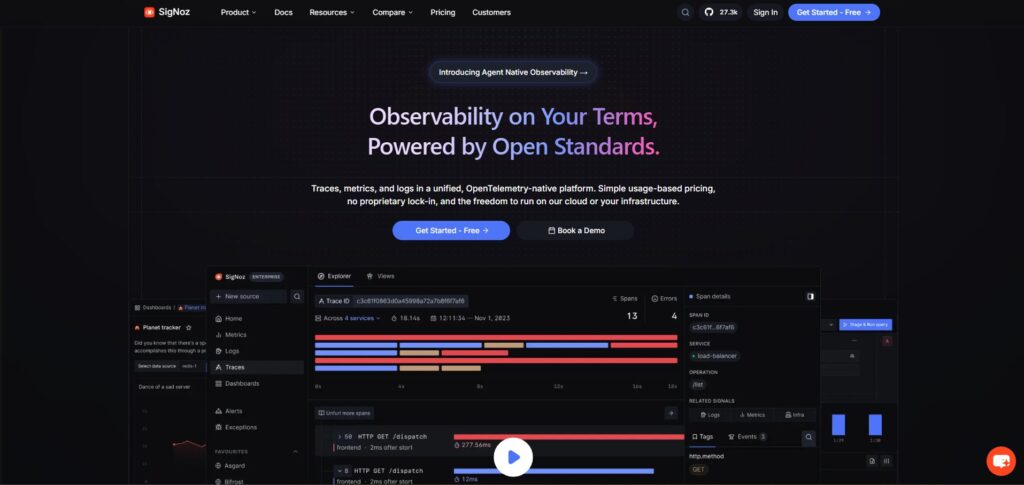
SigNoz เป็นเครื่องมือแรกที่เราจะประเมินสำหรับทีมที่ต้องการการสังเกตการณ์ LLM ภายในสแต็กการสังเกตการณ์วิศวกรรมที่กว้างขึ้น มันเป็น OpenTelemetry-native และนำร่องรอย, เมตริก, ล็อก, ข้อยกเว้น, แดชบอร์ด และการแจ้งเตือนมารวมกันในแพลตฟอร์มเดียว.
ที่ ShareAI เราใช้ SigNoz เป็นชั้นการสังเกตการณ์และการติดตามแบบครบวงจรของเรา ซึ่งสำคัญเพราะปัญหา AI มักไม่อยู่ในขอบเขตของการเรียกโมเดลเดียว การตอบสนองที่ไม่ดีสามารถเกี่ยวข้องกับความล่าช้าของ API, การกำหนดเส้นทางผู้ให้บริการ, การลองใหม่, เวลาฐานข้อมูล, พฤติกรรมคิว, เหตุการณ์การเรียกเก็บเงิน และข้อผิดพลาดในระดับแอป SigNoz ให้ทีมมีที่เดียวในการเชื่อมโยงสัญญาณเหล่านั้นแทนที่จะกระโดดไปมาระหว่างเครื่องมือที่ไม่เชื่อมโยงกัน.
SigNoz มีความแข็งแกร่งเป็นพิเศษเมื่อคุณต้องการให้ร่องรอย LLM อยู่ข้างๆ การสังเกตการณ์แอปพลิเคชันและโครงสร้างพื้นฐานปกติ สำหรับทีมที่คิดใน OpenTelemetry, แผนที่บริการ, ร่องรอยความล่าช้า, การเชื่อมโยงล็อก และการแจ้งเตือนอยู่แล้ว นั่นทำให้ SigNoz เป็นพื้นฐานที่ใช้งานได้จริงสำหรับระบบ AI ในการผลิต.
เหมาะสำหรับ: ทีมที่ต้องการการสังเกตการณ์ LLM, การสังเกตการณ์แอป, สัญญาณโครงสร้างพื้นฐาน และการติดตามในที่เดียว.
2. Langfuse
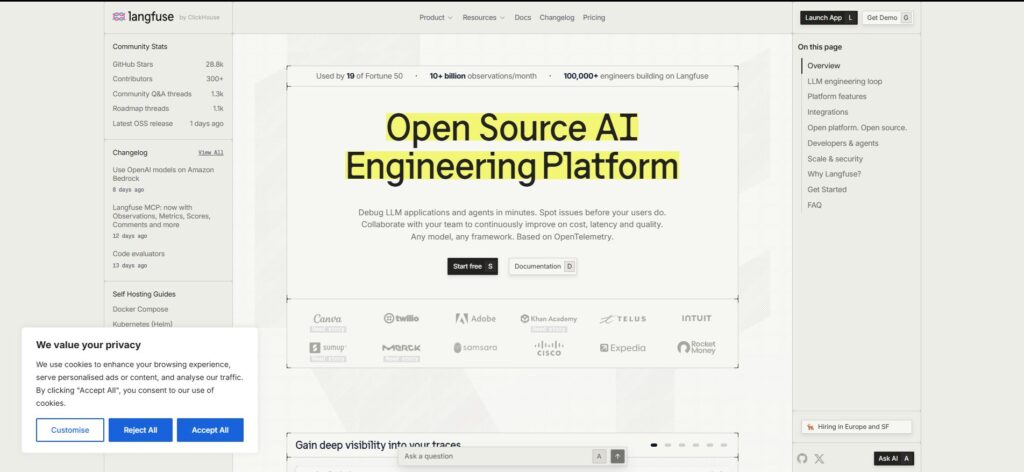
Langfuse เป็นตัวเลือกโอเพ่นซอร์สที่แข็งแกร่งสำหรับการติดตามแอปพลิเคชัน LLM มันถูกสร้างขึ้นรอบๆ ร่องรอย, เซสชัน, การสังเกตการณ์, การใช้โทเค็น, ความล่าช้า, การจัดการคำสั่ง, ชุดข้อมูล, การทดลอง และการประเมินผล.
Langfuse เหมาะสมเมื่อเวิร์กโฟลว์วิศวกรรม AI เองเป็นศูนย์กลางของแรงโน้มถ่วง หากทีมของคุณต้องการการวนซ้ำคำสั่ง, การตรวจสอบร่องรอย, การติดตามค่าใช้จ่าย และเวิร์กโฟลว์การประเมินในอินเทอร์เฟซ LLM ที่สร้างขึ้นเพื่อวัตถุประสงค์ Langfuse เป็นหนึ่งในตัวเลือกที่ชัดเจนที่สุด.
เหมาะสำหรับ: ทีมพัฒนาที่ต้องการการติดตาม LLM แบบโอเพ่นซอร์ส, การจัดการคำสั่ง และเวิร์กโฟลว์การประเมิน.
3. LangSmith
LangSmith เป็นตัวเลือกที่เหมาะสมสำหรับทีมที่สร้างด้วย LangChain หรือ LangGraph โดยเน้นการติดตาม การตรวจสอบ การประเมิน การแจ้งเตือน และการแก้ไขข้อบกพร่องในแอป LLM และตัวแทน.
ข้อได้เปรียบหลักคือความเหมาะสมของระบบนิเวศ หากทีมของคุณใช้งาน LangChain อย่างหนัก LangSmith สามารถทำให้การติดตาม การประเมินผล และการแก้ไขข้อบกพร่องของตัวแทนรู้สึกใกล้เคียงกับเวิร์กโฟลว์การพัฒนา.
เหมาะสำหรับ: ทีม LangChain และ LangGraph ที่ต้องการการสังเกตการณ์ที่เชื่อมโยงอย่างแน่นหนากับกรอบงานตัวแทนของพวกเขา.
4. เฮลิคอน

Helicone มีประโยชน์สำหรับทีมที่ต้องการชั้นการสังเกตการณ์ที่เบา ๆ รอบการรับส่งข้อมูล API ที่เข้ากันได้กับ OpenAI โดยมักจะดึงดูดเมื่อปัญหาแรกเป็นเรื่องง่าย: ดูคำขอ ความหน่วง การใช้งานโมเดล ข้อผิดพลาด ผู้ใช้ และค่าใช้จ่ายโดยไม่ต้องสร้างชั้นวิเคราะห์แบบกำหนดเอง.
Helicone ไม่ใช่แพลตฟอร์มการสังเกตการณ์แบบเต็มรูปแบบที่ลึกที่สุดเสมอไป แต่มีความเหมาะสมสำหรับทีมที่ต้องการการมองเห็นระดับ API อย่างรวดเร็วและการตรวจสอบค่าใช้จ่ายในสายเรียก LLM.
เหมาะสำหรับ: สตาร์ทอัพและทีมผลิตภัณฑ์ที่ต้องการการสังเกตการณ์ API LLM อย่างรวดเร็วและการมองเห็นการใช้งาน.
5. อะไรซ์ ฟีนิกซ์

อะไรซ์ ฟีนิกซ์ เป็นแพลตฟอร์มการสังเกตการณ์และการประเมิน AI แบบโอเพ่นซอร์ส โดยรองรับการติดตาม การออกแบบคำสั่ง ชุดข้อมูล การทดลอง และเวิร์กโฟลว์การประเมิน พร้อมการสนับสนุนเครื่องมือ OpenTelemetry และ OpenInference.
Phoenix มีประโยชน์เมื่อการแก้ไขข้อบกพร่องไม่เพียงพอและคุณต้องปรับปรุงคุณภาพผลลัพธ์ด้วยข้อมูลการประเมิน ทีมสามารถตรวจสอบการทำงานแต่ละรายการ ให้คะแนนผลลัพธ์ เปรียบเทียบการเปลี่ยนแปลงคำสั่ง และเปลี่ยนพฤติกรรมการผลิตให้เป็นหลักฐานสำหรับการทำซ้ำ.
เหมาะสำหรับ: ทีมที่ใส่ใจเกี่ยวกับการประเมิน LLM การทดลอง และการปรับปรุงคุณภาพเท่ากับการตรวจสอบการติดตาม.
6. พรอมต์เลเยอร์
พรอมต์เลเยอร์ รวมการสังเกตการณ์เข้ากับการจัดการคำสั่ง โดยติดตามคำขอ ช่วง ค่าใช้จ่าย ความหน่วง เวอร์ชันคำสั่ง และการวิเคราะห์ เพื่อให้ทีมเข้าใจทั้งพฤติกรรมการผลิตและการเปลี่ยนแปลงคำสั่ง.
PromptLayer เหมาะสมอย่างยิ่งเมื่อการดำเนินการเกี่ยวกับ prompt เป็นกระบวนการหลัก หากทีมของคุณมักถามว่าเวอร์ชัน prompt ใดทำให้เกิดการถดถอย คำขอใดที่ล้มเหลว หรือ prompt ทำงานอย่างไรในโมเดลต่างๆ PromptLayer จะเก็บประวัติไว้ใกล้กับวงจรการดีบัก.
เหมาะสำหรับ: ทีมที่ต้องการการจัดการเวอร์ชัน prompt การวิเคราะห์ prompt และการสังเกตการณ์คำขอ LLM รวมกัน.
เครื่องมือสังเกตการณ์ LLM ที่เปรียบเทียบกัน
| เครื่องมือ | เหมาะสมที่สุด | จุดแข็งหลัก |
|---|---|---|
| SigNoz | การสังเกตการณ์ AI และแอปแบบครบวงจร | การติดตามแบบ OpenTelemetry-native เมตริก ล็อก แดชบอร์ด และการแจ้งเตือน |
| Langfuse | ทีมวิศวกรรม LLM แบบโอเพ่นซอร์ส | การติดตาม LLM การจัดการ prompt ชุดข้อมูล และการประเมินผล |
| LangSmith | ทีม LangChain และ LangGraph | การติดตาม การตรวจสอบ และการประเมินผลที่เชื่อมต่อกับเฟรมเวิร์ก |
| เฮลิคอน | การมองเห็น LLM ระดับ API อย่างรวดเร็ว | บันทึกคำขอ การใช้งาน ความล่าช้า ข้อผิดพลาด และการติดตามต้นทุน |
| อะไรซ์ ฟีนิกซ์ | แอป AI ที่เน้นการประเมินผล | การติดตาม การทดลอง ชุดข้อมูล และการประเมินคุณภาพ |
| พรอมต์เลเยอร์ | การดำเนินการเกี่ยวกับ prompt | เวอร์ชันของ Prompt, การติดตามคำขอ, ความหน่วงเวลา, ค่าใช้จ่าย และการวิเคราะห์ |
ตำแหน่งของ ShareAI ในระบบ Observability Stack
ShareAI ไม่ใช่ตัวแทนของ SigNoz, Langfuse, LangSmith หรือแพลตฟอร์ม Observability อื่น ๆ แต่เป็นตลาด AI และ API ที่ช่วยให้ลูกค้าและผู้สร้างสามารถเข้าถึงโมเดลกว่า 150+ ผ่านการรวมระบบเดียว, การจัดเส้นทางคำขอ, การใช้ระบบสำรองอัจฉริยะ และการติดตามการใช้งาน AI ผ่านชั้นการเข้าถึงโมเดล.
สำหรับผู้สร้าง ShareAI มีประโยชน์เมื่อแอปพลิเคชันถูกสร้างขึ้นนอก ShareAI แต่การจราจร AI ของมันต้องการการจัดเส้นทาง, การติดตามการใช้งาน, การเรียกเก็บเงิน, การควบคุมค่าบริการ และการจ่ายเงินรายเดือนให้กับผู้สร้าง เครื่องมือ Observability แสดงสิ่งที่เกิดขึ้น ShareAI ช่วยควบคุมวิธีการจัดเส้นทางและการสร้างรายได้จากการจราจร AI inference.
การตั้งค่าที่แข็งแกร่งที่สุดคือการรวมทั้งสองชั้น ใช้ ShareAI สำหรับการเข้าถึงโมเดลและการใช้งาน AI ที่จัดเส้นทาง ใช้ SigNoz หรือแพลตฟอร์ม Observability อื่น ๆ เพื่อเชื่อมโยงการติดตาม AI กับแอปพลิเคชัน, โครงสร้างพื้นฐาน และกระบวนการตอบสนองเหตุการณ์ของคุณ.
เพื่อเชื่อมต่อชั้นการเข้าถึงโมเดล เริ่มต้นด้วย เอกสารอ้างอิง API ของ ShareAI. เพื่อเปรียบเทียบโมเดลก่อนจัดเส้นทางการจราจร ให้เรียกดู ตลาดโมเดล ShareAI.
คำถามที่พบบ่อย
เครื่องมือ Observability LLM ที่ดีที่สุดคืออะไร?
เครื่องมือ Observability LLM ที่ดีที่สุดขึ้นอยู่กับกระบวนการทำงาน SigNoz แข็งแกร่งสำหรับการ Observability แบบเต็มสแต็ก Langfuse สำหรับการติดตาม LLM แบบโอเพ่นซอร์ส LangSmith สำหรับทีม LangChain Phoenix สำหรับกระบวนการที่เน้นการประเมิน และ PromptLayer สำหรับการดำเนินการ Prompt.
ทำไม SigNoz ถึงอยู่ในรายการนี้เป็นอันดับแรก?
SigNoz อยู่ในอันดับแรกเพราะมันเชื่อมโยงการติดตาม LLM กับการวัดผลแอปพลิเคชันที่กว้างขึ้น ที่ ShareAI เราใช้ SigNoz เป็นชั้น Observability และการติดตามหลักของเรา เพราะเหตุการณ์ AI มักเกี่ยวข้องกับโมเดล, API, ฐานข้อมูล, คิว, ล็อก, เมตริก และโครงสร้างพื้นฐานร่วมกัน.
Observability LLM คืออะไร?
Observability LLM คือการปฏิบัติในการติดตาม, วัดผล, บันทึก และประเมินพฤติกรรมแอปพลิเคชัน AI โดยปกติจะรวมถึง Prompt, การตอบสนอง, การเรียกใช้เครื่องมือ, ขั้นตอนการดึงข้อมูล, การใช้งานโทเค็น, ค่าใช้จ่าย, ความหน่วงเวลา, ข้อผิดพลาด และสัญญาณคุณภาพของผลลัพธ์.
Observability LLM แตกต่างจากการบันทึกปกติอย่างไร?
การบันทึกแบบปกติจะบันทึกเหตุการณ์ต่างๆ การสังเกตการณ์ LLM จะสร้างกระบวนการทำงานของ AI ทั้งหมดขึ้นใหม่ รวมถึงข้อมูลนำเข้าและส่งออกของโมเดล ขั้นตอนกลาง การเรียกใช้เครื่องมือ ค่าใช้จ่าย และคุณภาพ ช่วยให้ทีมเข้าใจว่าทำไมการตอบสนองของ AI ถึงเกิดขึ้น ไม่ใช่แค่การร้องขอที่เกิดขึ้น.
ฉันจำเป็นต้องใช้การสังเกตการณ์ LLM หากฉันใช้ AI gateway อยู่แล้วหรือไม่?
ใช่ AI gateway สามารถช่วยจัดเส้นทาง วัดผล และควบคุมการเข้าถึงโมเดล ในขณะที่เครื่องมือสังเกตการณ์ช่วยแก้ไขข้อบกพร่องและตรวจสอบพฤติกรรมในแอปพลิเคชันทั้งหมด ชั้นทั้งสองนี้แก้ปัญหาที่แตกต่างกันแต่เสริมกัน.
ShareAI แทนที่เครื่องมือสังเกตการณ์ได้หรือไม่?
ไม่ ShareAI เป็นตลาด AI และ API สำหรับการเข้าถึงโมเดล การจัดเส้นทาง การใช้งาน การเรียกเก็บเงิน และการสร้างรายได้ของ Builder ควรจับคู่กับแพลตฟอร์มสังเกตการณ์เช่น SigNoz เมื่อทีมต้องการการติดตามเต็มรูปแบบ บันทึก เมตริก แดชบอร์ด และการแจ้งเตือน.
ทีมควรติดตามอะไรในแอป LLM?
ทีมควรติดตามคำร้องขอของผู้ใช้ เวอร์ชันของคำสั่ง การเรียกโมเดล ขั้นตอนการดึงข้อมูล การเรียกใช้เครื่องมือ การลองใหม่ การสำรองข้อมูล การใช้โทเค็น ความล่าช้า สถานะข้อผิดพลาด และการตรวจสอบคุณภาพผลลัพธ์ สำหรับตัวแทน การเลือกเครื่องมือและลำดับการดำเนินการมีความสำคัญเป็นพิเศษ.
เครื่องมือสังเกตการณ์ LLM ใดดีที่สุดสำหรับทีมโอเพ่นซอร์ส?
SigNoz, Langfuse, Arize Phoenix และ WhyLabs LangKit ล้วนมีมุมมองโอเพ่นซอร์สที่แข็งแกร่ง ตัวเลือกที่เหมาะสมขึ้นอยู่กับว่าทีมต้องการการวัดผลแบบเต็มสแต็ก การติดตามเฉพาะ LLM เวิร์กโฟลว์การประเมิน หรือการตรวจสอบคุณภาพผลลัพธ์.
เครื่องมือสังเกตการณ์ LLM ใดดีที่สุดสำหรับ LangChain?
LangSmith เป็นตัวเลือกที่เหมาะสมที่สุดสำหรับทีมที่ใช้ LangChain หรือ LangGraph อยู่แล้ว Langfuse และ Phoenix ก็สามารถทำงานได้ดีขึ้นอยู่กับโมเดลการติดตาม การประเมิน และการโฮสต์ที่ทีมชื่นชอบ.
การสังเกตการณ์ช่วยควบคุมค่าใช้จ่ายของ AI ได้อย่างไร?
การสังเกตการณ์เชื่อมโยงค่าใช้จ่ายกับผู้ใช้ โมเดล คำสั่ง เส้นทาง แอปพลิเคชัน และเวิร์กโฟลว์ ช่วยให้ทีมค้นหาคำสั่งที่มีค่าใช้จ่ายสูง วงวนที่ไม่สามารถควบคุมได้ เส้นทางที่มีความล่าช้าสูง การลองใหม่ซ้ำๆ และฟีเจอร์ที่มีการใช้งานสูงกว่าที่คาดไว้มาก.
Builder สามารถสร้างรายได้จากแอป AI และยังใช้การสังเกตการณ์ได้หรือไม่?
ได้ Builder สามารถจัดเส้นทางการประมวลผล AI จากแอปผ่าน ShareAI กำหนดส่วนต่างหรือค่าบริการเพิ่มเติม และยังใช้ SigNoz หรือเครื่องมือสังเกตการณ์อื่นๆ เพื่อตรวจสอบแอปพลิเคชัน การติดตาม บันทึก ข้อผิดพลาด และประสิทธิภาพ.

